
Vorgeschichte
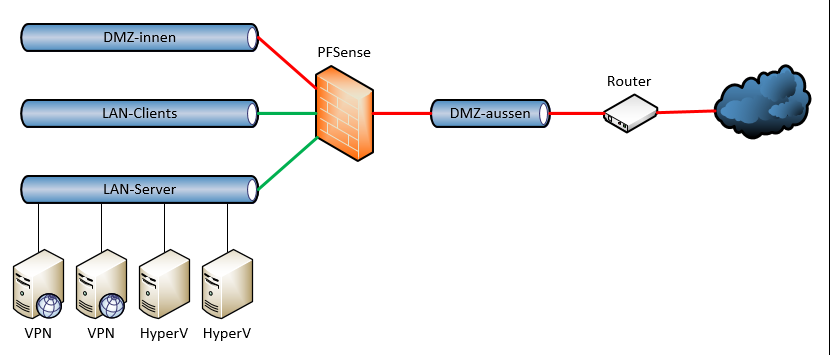
Die PFSense-Firewall sollte kostengünstig und ausfallsicher sein. Also installierte ich sie in eine virtuelle Maschine auf meinem Hyper-V-FailoverCluster, der aus 2 Servern bestand. Sollte einer der Server ausfallen, dann würde die VM auf dem anderen weiterlaufen bzw. wieder gestartet werden.
Für die Administration und den Zugriff auf Daten von unterwegs setzte ich 2 VPN-Server ein. Dieser waren im Netz „LAN-Server“ angeschlossen – also hinter der Firewall. Im Normalbetrieb ist das kein Problem. Aber was wäre, wenn die PFSense nicht funktioniert? Richtig: Dann wäre auch kein VPN-Zugriff und damit kein TroubleShooting möglich!
Natürlich hätte ich auch die beiden VPN-Server in die „DMZ-aussen“ platzieren können. Aber die Verteilung der Verbindungen auf beide Server übernimmt ein HAProxy – ein Zusatzmodul in der PFSense, denn mein Router kann kein PortForwarding mit 1:n. Somit hätte ich nur einen VPN-Server einsetzen können. Und dann wäre das Problem mit der Verfügbarkeit nur verschoben.
So entschied ich mich, den beiden HyperV-Servern einen Zugang zum Netz „DMZ-aussen“ zu konfigurieren:
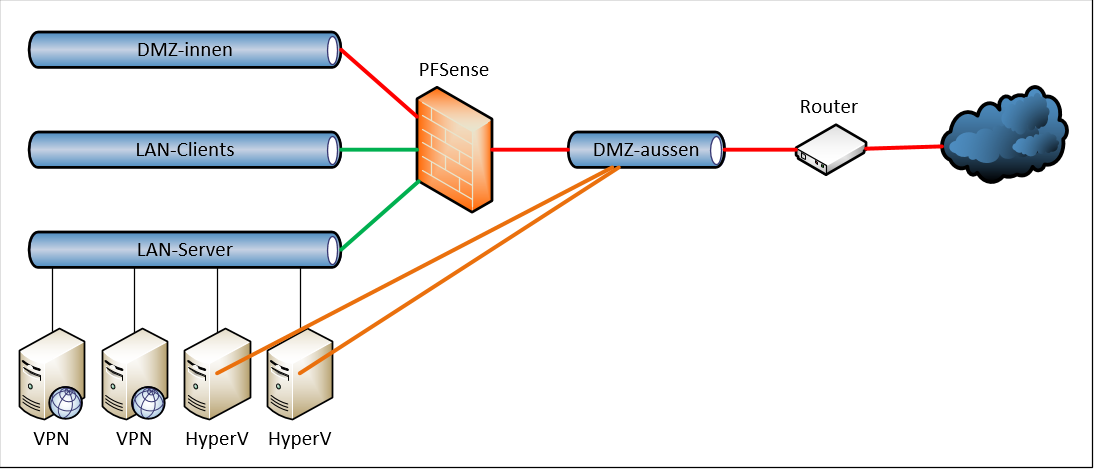
So konnte ich auf meinem Router direkt ein PortForwarding auf den RDP-Port 3389 einrichten (Hinweis: mach das blos nicht nach!). Damit es nach außen nicht so offensichtlich ist habe ich für extern einen anderen Port gewählt (Security by Obscurity == FacePalm):
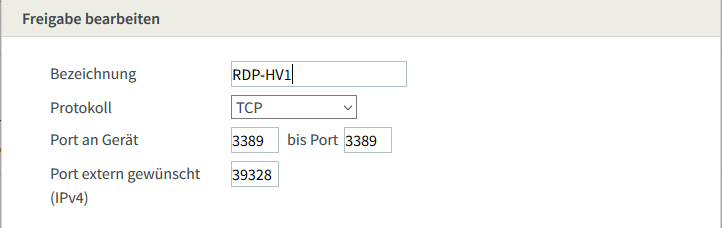
So konnte ich von außen im Notfall direkt auf meine HyperV-Server zugreifen und die VM PFSense reparieren bzw. starten. Und wer scannt schon die higher Ports…
Mittlerweile verwende ich 2 PFSense-VMs, die als CARP-Cluster alle Funktionen für den Netzwerkschutz übernehmen. Je eine läuft auf einem HyperV-Server. Somit war kein Cluster mehr erforderlich. Nur was soll ich sagen … die beiden Portfreigaben für den RDP-Zugriff hatte ich einfach vergessen!
Der Angriff
- eine Netzwerksegmentierung mit der PFSense und ihrer sauber konfigurierten Firewall
- ein Geoblocker, der Verbindungen nur aus bestimmten geographischen Regionen zulässt werkelt ebenfalls auf der PFSense
- der Einsatz eines Snort IPS für die Analyse der erlaubten Verbindungen in der PFSense mit einem PowerShell-Monitoring/Alerting per Mail
- eine Vielzahl an Richtlinien zur Absicherung meiner Systeme
- sogar ein Microsoft ATA (Advanced Thread Analytics) war im Einsatz – es sollte Anomalien beim Anmelden und beim Ressourcenzugriff erkennen und melden
- der Zugriff auf die beiden HyperV-Server war durch MFA abgesichert
Nur leider hatte die Konfiguration eine Schwachstelle: alle Netzwerkschutzkomponenten wurden von der PFSense ausgeführt. Und meine beiden HyperV-Hosts hatten einen Bypass!
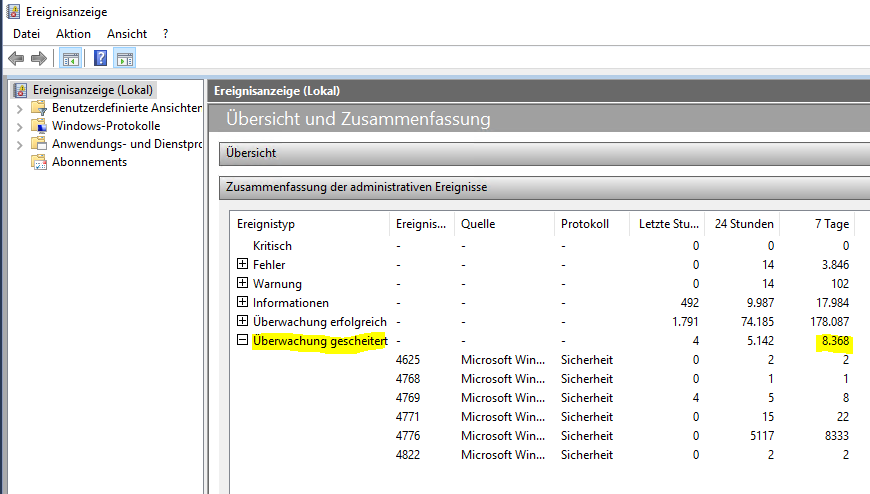
Ich kenne meine Infrastruktur. Diese Anzahl an AuditFailures ist nicht normal. Also ging ich in die Analyse. Und wurde überrascht:
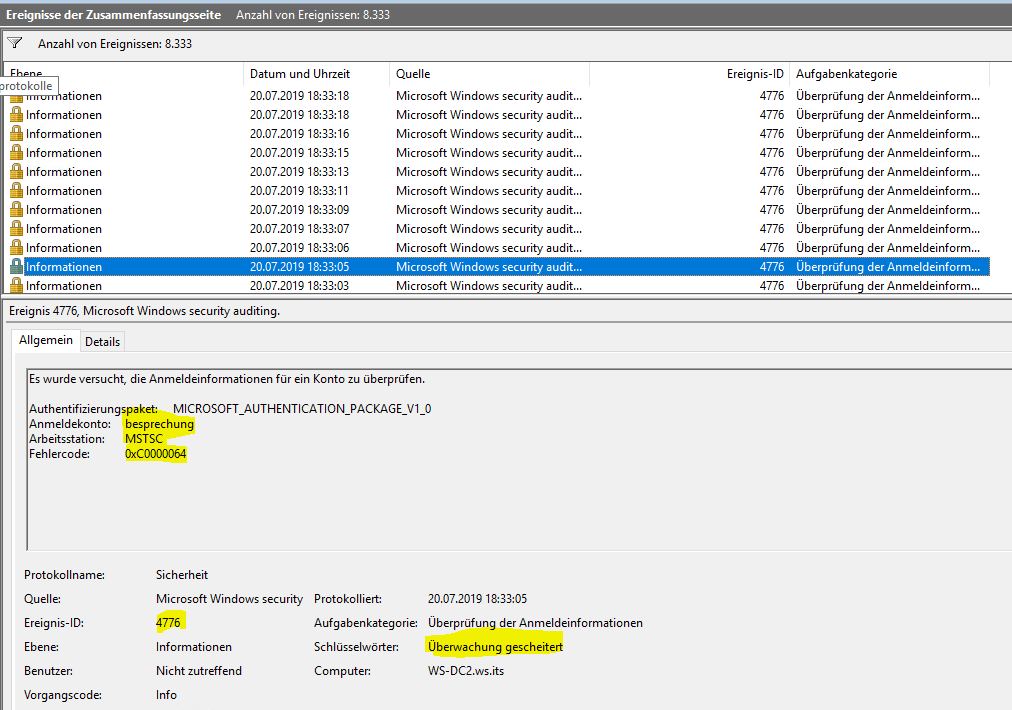
Und jeder Eintrag listete ein anderes Anmeldekonto. Ganz klar: hier versuchte jemand mit verschiedenen Benutzernamen (und Passwörtern) einen BruteForce-Angriff auf meine Infrastruktur!
In meinem Fall wusste ich sehr schnell, dass es sich um eine Bruteforce-Attacke handelte. Dabei werden Benutzernamen und Passwörter durchprobiert, bis es einen Treffer gibt. Mir konnte also nichts passieren, denn:
- mit dem falschen Benutzernamen gibt es keinen Zutritt
- mit dem richtigen Benutzernamen greift die Lockout-Policy nach x fehlerhaften Anmeldungen
Und dann kommen meine zusätzlichen Schutzmaßnahmen.
Ich hatte also Zeit und vor allem die Gelegenheit, mir den Angriff mal etwas näher anzusehen. Zunächst wollte ich herausfinden, welcher Service auf welchem Server für das bruteforcen mißbraucht wurde – der Patient Null. Nur leider findet man in dem Eventlog auf dem DomainController keinen Hinweis ab den „Auftraggeber“ der Anmeldeüberprüfung. Aber ich habe ein anderes Script, das mir jeden Tag über alle Server eine Zusammenfassung der letzten 24 Stunden liefert. Und darunter befinden sich auch die kumulierten Eventlogs je Server:
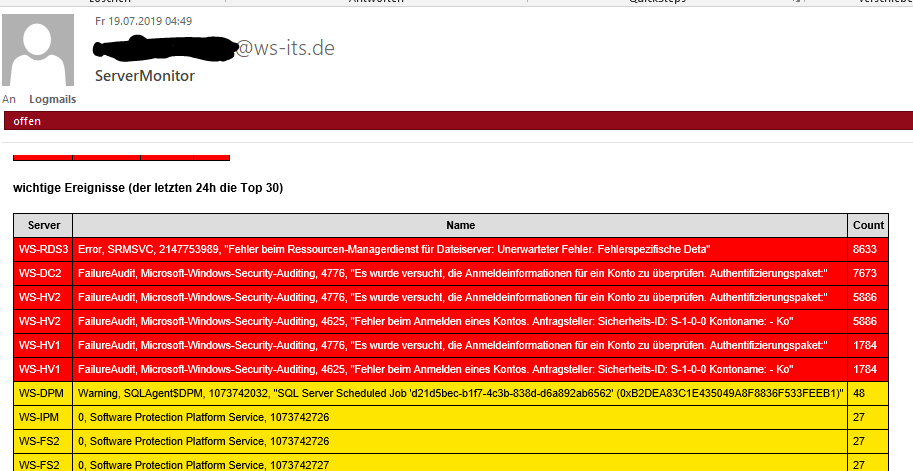
2 Treffer sind erkennbar: WS-HV1 und WS-HV2 – meine beiden HyperV-Hosts. Auf diesen fand ich die Eventlogs:
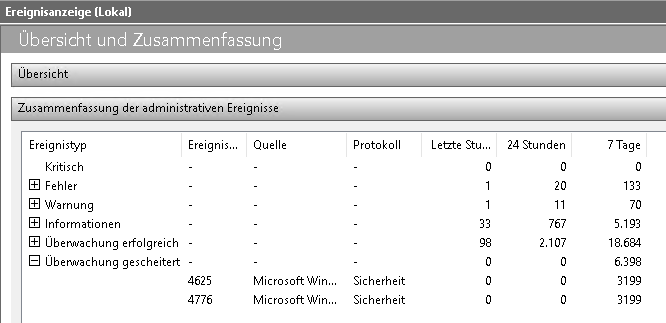
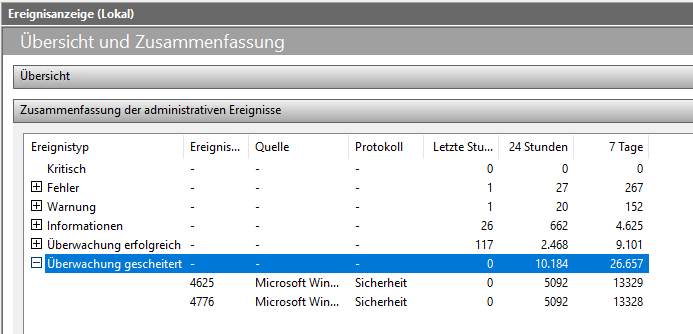
Und in den Details gab es die Antwort auf den Ursprung:

Die Frage „Wurden auch andere Quell-IP-Adressen verwendet?“ konnten ein paar Zeilen PowerShell-Code beantworten:

Und wer ist der Angreifer?
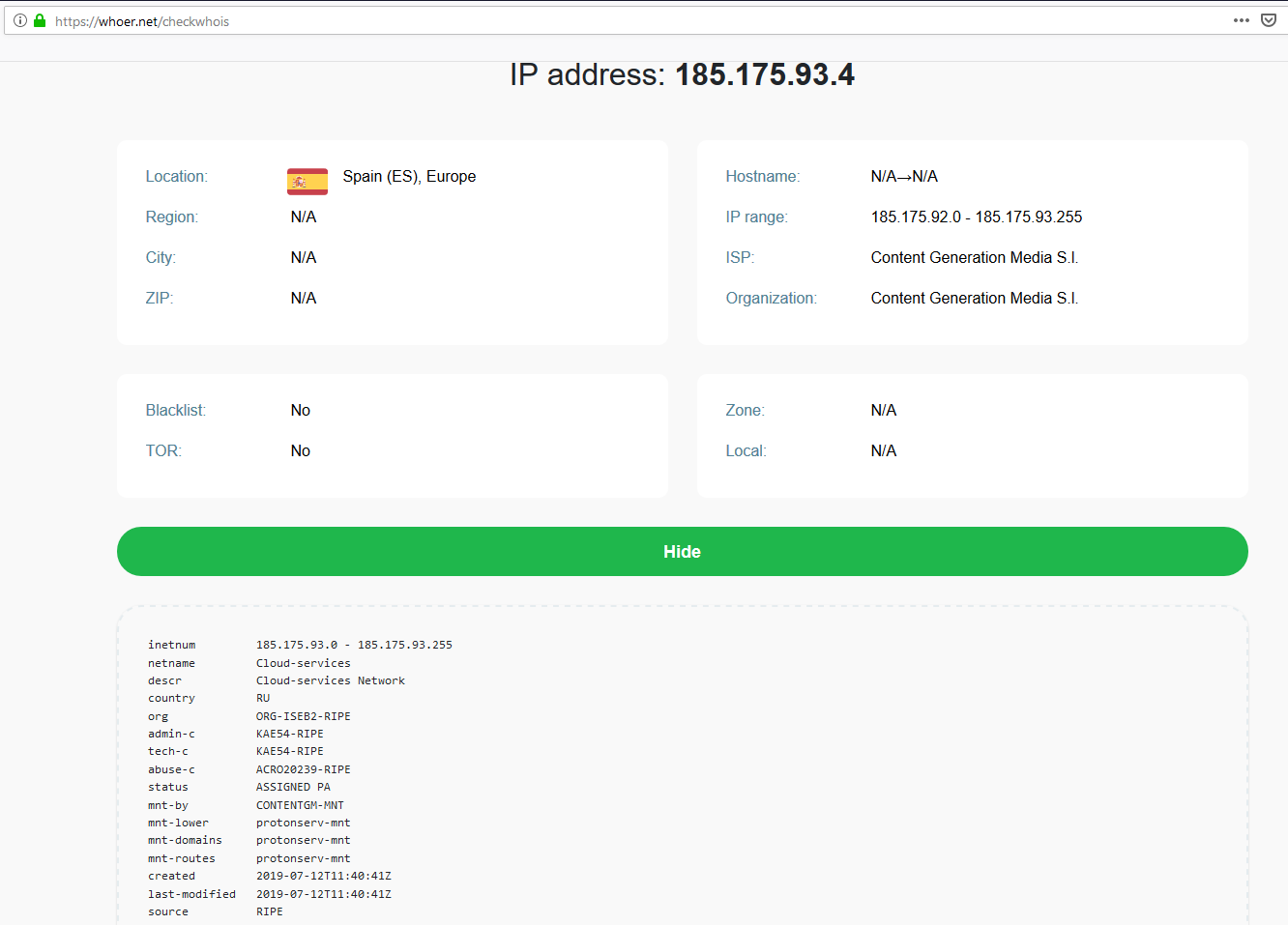
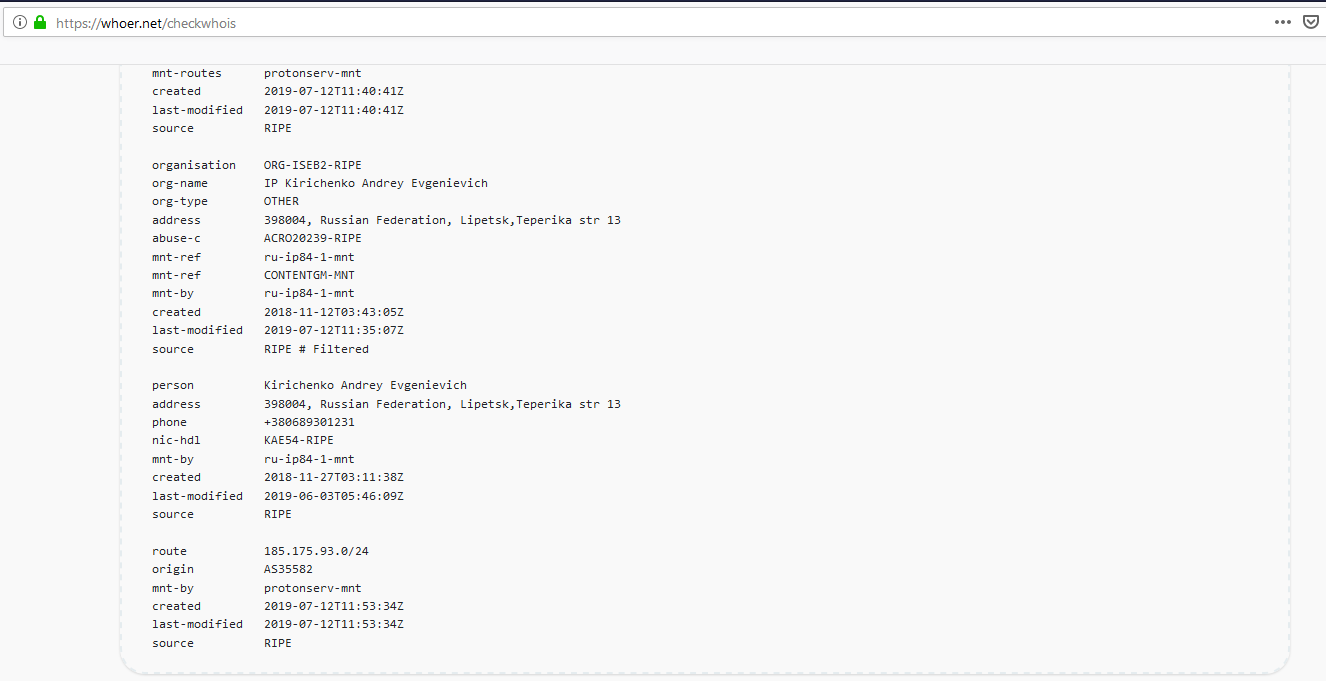
Sieht nicht sehr vielversprechend aus: außer einem russischen Namen gibt es keinen Hinweis. Manch einer würde sagen: die Russen waren es. Das würde ich nicht empfehlen. Wir fahren einen Nissan, sind aber keine Asiaten. Und eigentlich spielt es auch keine Rolle, da es sich an der Vorgehensweise bewertet nach einem gestreuten Angriff aussieht. Das wird auch deutlich, wenn man sich die verwendeten Benutzernamen anschaut:
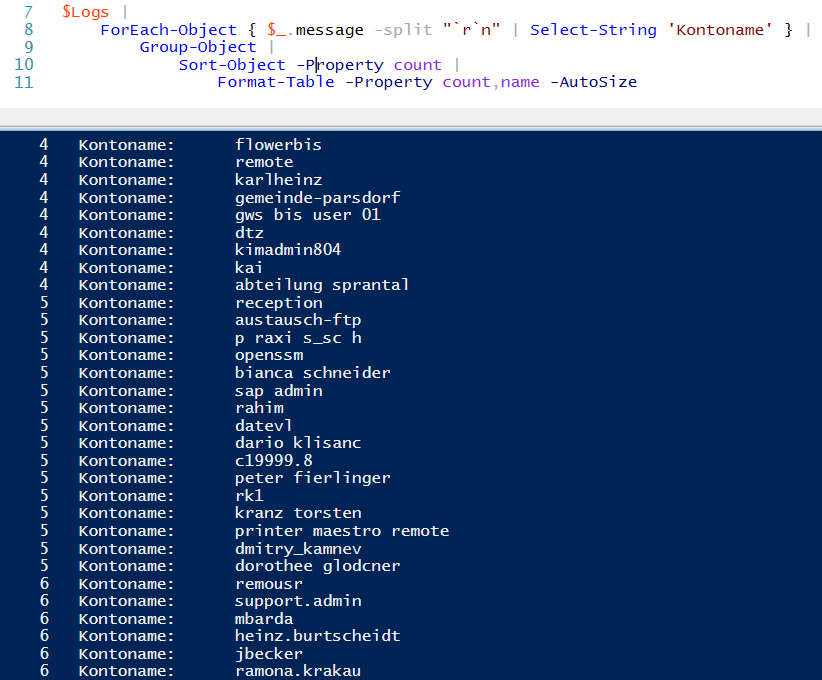
Spannend finde ich die Tatsache, dass hier zwischen einigen krypischen Namen auch deutsche Namen verwendet wurden. Ebenso die typischen Servicenamen „datev“ und „sap“, aber auch „support“ und „admin“ kommen nicht zu kurz. Und die Gemeinde Parsdorf ist auch nicht so weit weg. Ganz offensichtlich versuchen die Angreifer durch zielorientierte Benutzernamen ihre Chancen zu erhöhen!
PS C:\Program Files (x86)\Nmap> .\nmap -sV -T4 -O -A -v -F -Pn --version-light 185.175.93.4
Starting Nmap 7.70 ( https://nmap.org ) at 2019-07-21 15:44 Mitteleuropõische Sommerzeit
NSE: Loaded 148 scripts for scanning.
NSE: Script Pre-scanning.
Initiating NSE at 15:44
Completed NSE at 15:44, 0.00s elapsed
Initiating NSE at 15:44
Completed NSE at 15:44, 0.00s elapsed
Initiating Parallel DNS resolution of 1 host. at 15:45
Completed Parallel DNS resolution of 1 host. at 15:45, 11.01s elapsed
Initiating SYN Stealth Scan at 15:45
Scanning 185.175.93.4 [100 ports]
Discovered open port 80/tcp on 185.175.93.4
Discovered open port 21/tcp on 185.175.93.4
Discovered open port 1720/tcp on 185.175.93.4
Discovered open port 3389/tcp on 185.175.93.4
Discovered open port 445/tcp on 185.175.93.4
Discovered open port 135/tcp on 185.175.93.4
Discovered open port 139/tcp on 185.175.93.4
Discovered open port 5800/tcp on 185.175.93.4
Discovered open port 9999/tcp on 185.175.93.4
Discovered open port 5432/tcp on 185.175.93.4
Discovered open port 2121/tcp on 185.175.93.4
Discovered open port 6000/tcp on 185.175.93.4
Increasing send delay for 185.175.93.4 from 0 to 5 due to max_successful_tryno increase to 5
Discovered open port 3128/tcp on 185.175.93.4
Increasing send delay for 185.175.93.4 from 5 to 10 due to max_successful_tryno increase to 6
Warning: 185.175.93.4 giving up on port because retransmission cap hit (6).
Completed SYN Stealth Scan at 15:45, 14.24s elapsed (100 total ports)
Initiating Service scan at 15:45
Scanning 13 services on 185.175.93.4
Completed Service scan at 15:46, 34.71s elapsed (13 services on 1 host)
Initiating OS detection (try #1) against 185.175.93.4
Retrying OS detection (try #2) against 185.175.93.4
Initiating Traceroute at 15:46
Completed Traceroute at 15:46, 3.05s elapsed
Initiating Parallel DNS resolution of 8 hosts. at 15:46
Completed Parallel DNS resolution of 8 hosts. at 15:46, 16.50s elapsed
NSE: Script scanning 185.175.93.4.
Initiating NSE at 15:46
Completed NSE at 15:46, 33.28s elapsed
Initiating NSE at 15:47
Completed NSE at 15:47, 0.01s elapsed
Nmap scan report for 185.175.93.4
Host is up (0.060s latency).
Not shown: 48 filtered ports, 39 closed ports
PORT STATE SERVICE VERSION
21/tcp open ftp?
80/tcp open tcpwrapped
| http-methods:
|_ Supported Methods: GET HEAD POST OPTIONS
|_http-title: Site doesn't have a title.
135/tcp open msrpc Microsoft Windows RPC
139/tcp open netbios-ssn Microsoft Windows netbios-ssn
445/tcp open microsoft-ds Microsoft Windows Server 2008 R2 - 2012 microsoft-ds
1720/tcp open tcpwrapped
2121/tcp open tcpwrapped
3128/tcp open tcpwrapped
3389/tcp open ssl/ms-wbt-server?
| ssl-cert: Subject: commonName=WIN-60DSI8SGOL6
| Issuer: commonName=WIN-60DSI8SGOL6
| Public Key type: rsa
| Public Key bits: 2048
| Signature Algorithm: sha1WithRSAEncryption
| Not valid before: 2019-04-17T16:14:17
| Not valid after: 2019-10-17T16:14:17
| MD5: 5f51 ef08 008c 93b9 9bf5 c506 c4c9 a467
|_SHA-1: 99d7 19d3 6400 6b9e 29d6 7f76 a73e 816b 2415 5969
|_ssl-date: 2019-07-21T13:46:25+00:00; -1s from scanner time.
5432/tcp open tcpwrapped
5800/tcp open tcpwrapped
6000/tcp open tcpwrapped
|_x11-access: ERROR: Script execution failed (use -d to debug)
9999/tcp open tcpwrapped
OS fingerprint not ideal because: Host distance (12 network hops) is greater than five
No OS matches for host
Network Distance: 12 hops
TCP Sequence Prediction: Difficulty=260 (Good luck!)
IP ID Sequence Generation: Randomized
Service Info: OSs: Windows, Windows Server 2008 R2 - 2012; CPE: cpe:/o:microsoft:windows
Host script results:
|_clock-skew: mean: -1s, deviation: 0s, median: -2s
| nbstat: NetBIOS name: WIN-60DSI8SGOL6, NetBIOS user: <unknown>, NetBIOS MAC: 18:66:da:a2:9c:ea (Dell)
| Names:
| WIN-60DSI8SGOL6<20> Flags: <unique><active>
| WORKGROUP<00> Flags: <group><active>
|_ WIN-60DSI8SGOL6<00> Flags: <unique><active>
| smb-security-mode:
| authentication_level: user
| challenge_response: supported
|_ message_signing: disabled (dangerous, but default)
| smb2-security-mode:
| 2.02:
|_ Message signing enabled but not required
| smb2-time:
| date: 2019-07-21 15:46:25
|_ start_date: 2019-04-29 09:38:14
TRACEROUTE (using port 53/tcp)
HOP RTT ADDRESS
1 2.00 ms 192.168.43.230
2 ...
3 29.00 ms 10.218.33.61
4 35.00 ms 10.218.35.137
5 37.00 ms 10.218.34.26
6 ... 7
8 46.00 ms de-cix1.RT.ACT.FKT.DE.retn.net (80.81.192.73)
9 70.00 ms ae0-1.RT.TLP.SOF.BG.retn.net (87.245.232.126)
10 65.00 ms GW-BelCloud.retn.net (87.245.248.211)
11 ...
12 68.00 ms 185.175.93.4
NSE: Script Post-scanning.
Initiating NSE at 15:47
Completed NSE at 15:47, 0.00s elapsed
Initiating NSE at 15:47
Completed NSE at 15:47, 0.00s elapsed
Read data files from: C:\Program Files (x86)\Nmap
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 136.47 seconds
Raw packets sent: 499 (24.424KB) | Rcvd: 181 (8.216KB)
Hier zeigt sich, dass die Maschine auf der anderen Seite mal so richtig viele offene Ports hat. Und alleine die Ports 135, 3389, 445 (Zeile 17,18,19) genügen mir für eine Vermutung: das ist ein Windows Rechner (Zeile 82), der direkt am Internet hängt. Und dieser wurde wahrscheinlich über SMB (445) oder RDP (3389) kompromittiert und soll mich nun als Bot weiter infizieren.
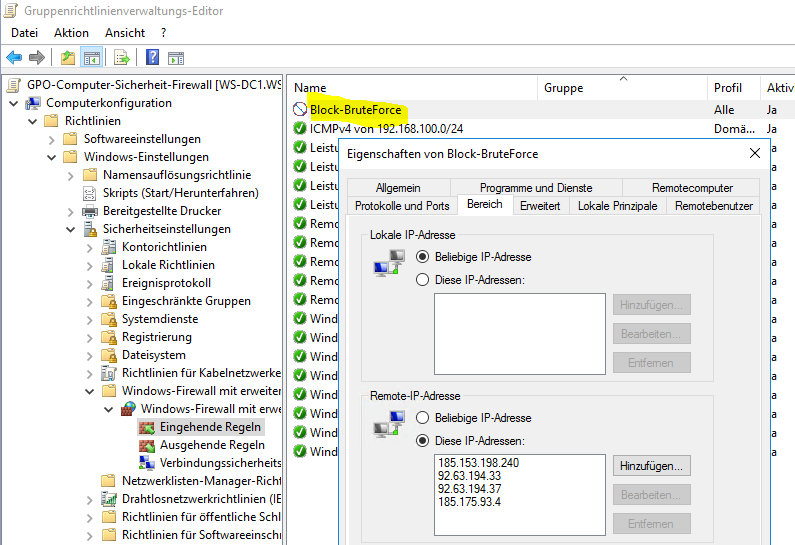
Ein gpupdate später war Ruhe.
Möglichkeiten der Erkennung
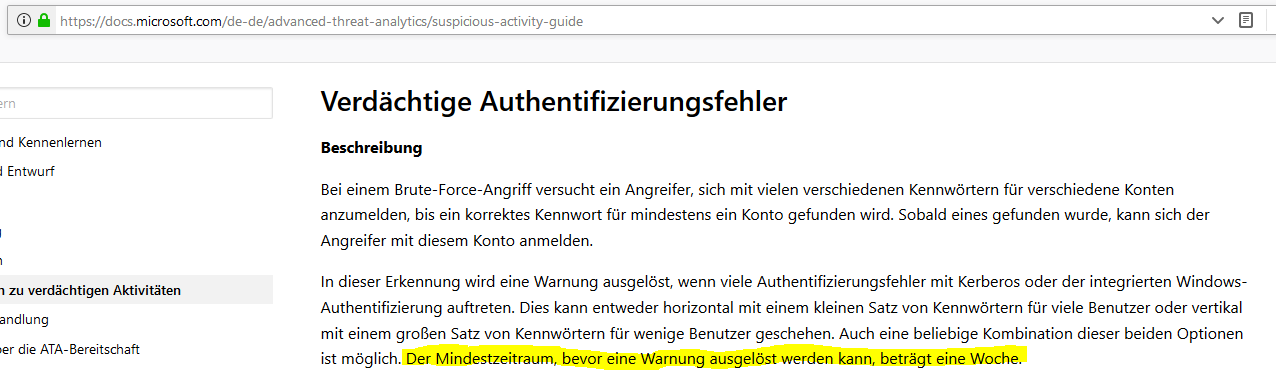
Ich kanns nicht fassen! Eine Woche würde ATA einfach schweigen. Bei der Angriffswelle wurde im Schnitt eine Anmeldung pro Sekunde versucht. Das macht dann 604.800 Anmeldeversuche, bevor eine Warnung aufploppt!!!
Hinweis: die Software des Hackers war nicht besonders clever, denn man kann an den Antwortzeiten einer Anmeldung erkennen, ob der Benutzername existiert oder nicht. Somit könnte in einer ersten Welle ein gültiger Anmeldename gesucht werden und in einer zweiten würde man dann alle möglichen Passwörter versuchen – natürlich vorsortiert nach deren Häufigkeit für eine bestimmte Zielgruppe. Und nun überlegen wir mal, an welcher Stelle in dieser Liste die Passwörter der Benutzer stehen. Vielleicht vor Nummer 604.800? …
Meine PFSense konnte mir nicht helfen, denn diese hatte ich ja selber umgangen. Was kann also helfen?
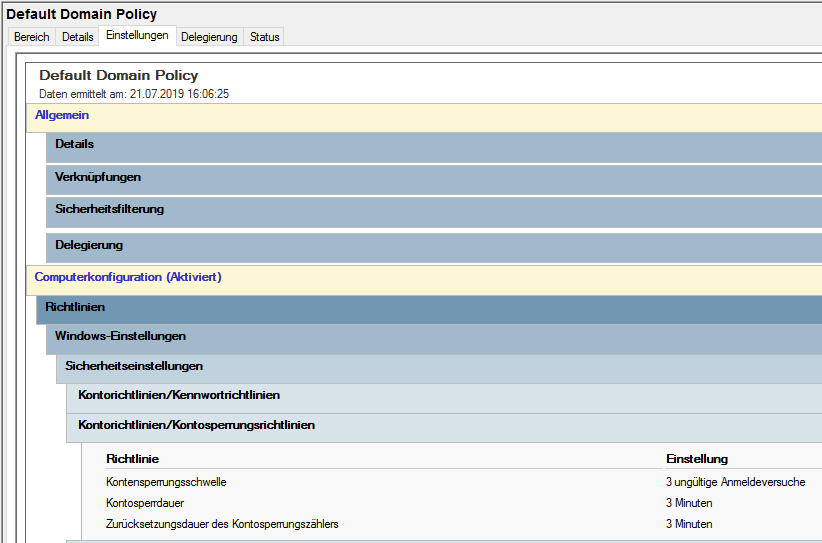
Seit Windows Server 2008 gibt es aber auch die Password Setting Objects (PSO) oder auch Finegrained Password Policies:
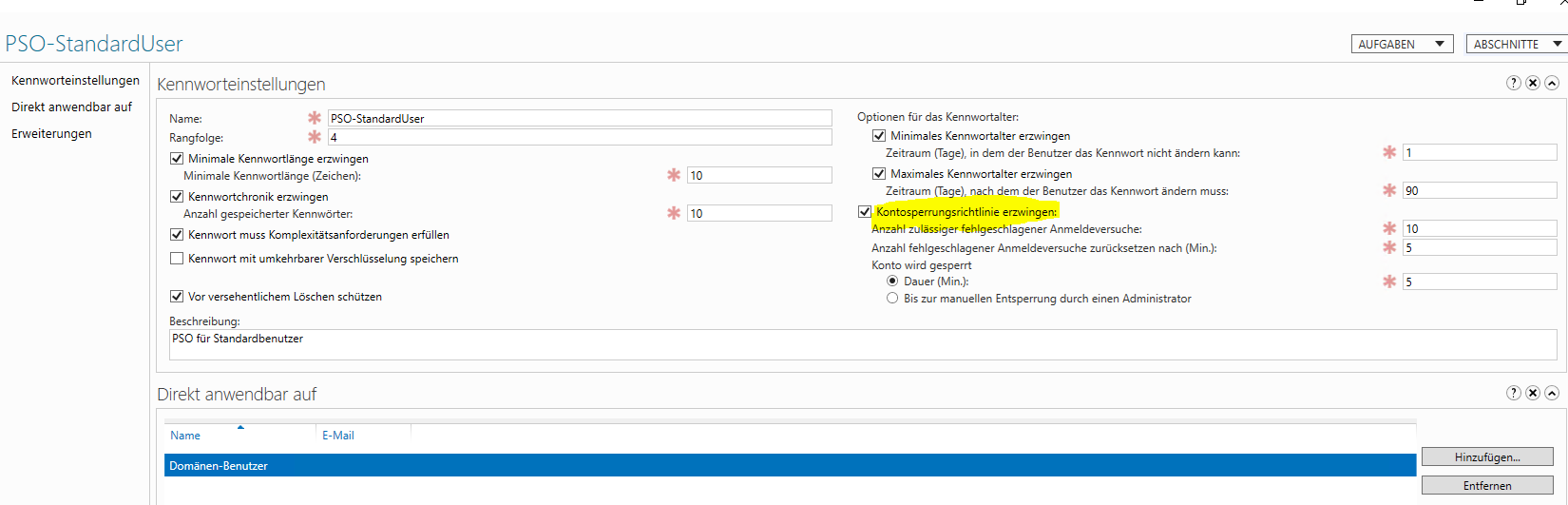
In meinem Fall wird ein Standardkonto nach 10 Fehlversuchen für 5 Minuten gesperrt. Damit ist kein Bruteforce-Angriff möglich.
Allein an den CSV-Dateien kann man schon Angriffe erkennen:
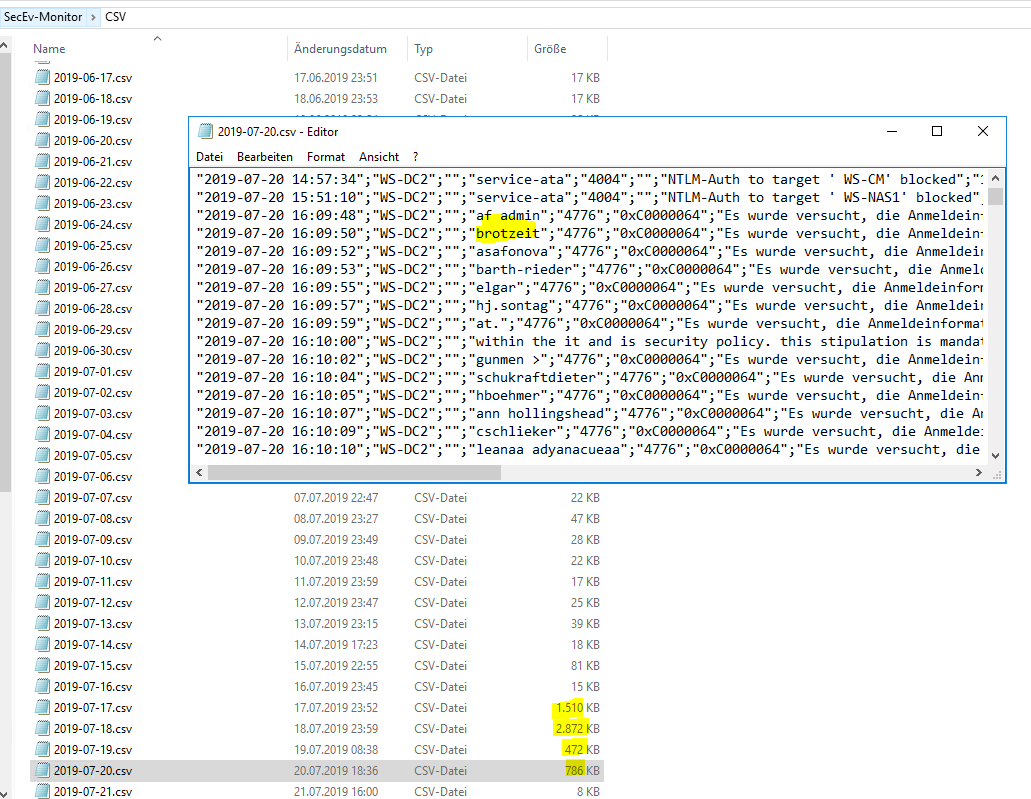
Besonders spannend ist aber die Darstellung und die Interpretation mit der PowerShell:
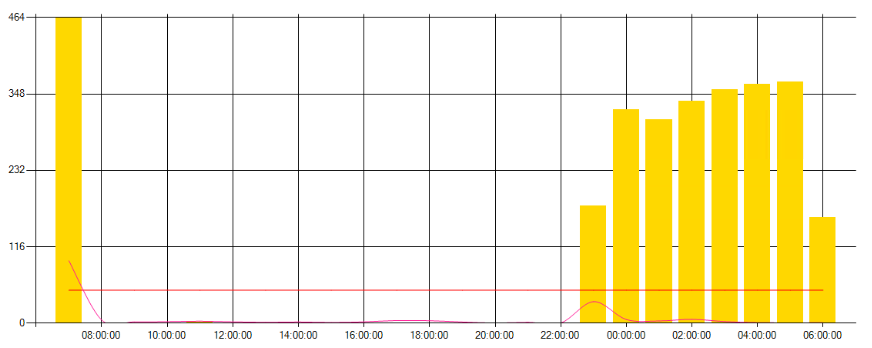
Die gelben Stapel repräsentieren die Anzahl der Events einer bestimmten Kategorie je Stunde. Die geschwungene Linie ist der Mittelwert der Events der gleichen Kategorie aus den letzten 4 Wochen – natürlich nur vom gleichen Wochentag (das musste einfach sein). Und die rote horizontale Linie ist mein persönlicher Schwellwert für den Alarm. Und dieser ging dann per Mail auch ein. Hier ein Beispiel vom 17.07.2019. Der Angriff startete 20:03 und die erste Mail kam 20:06:
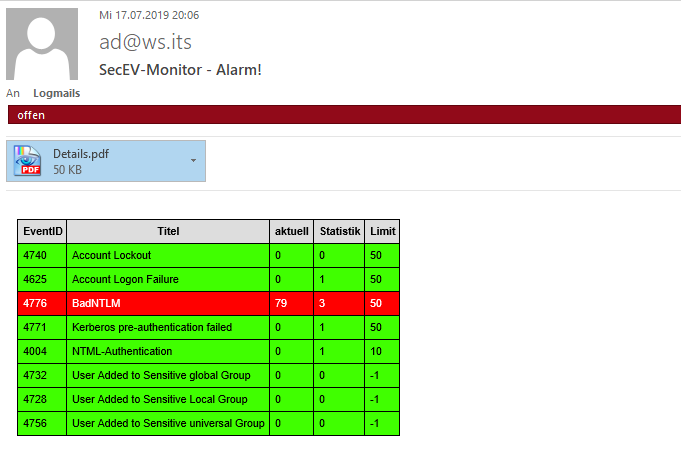
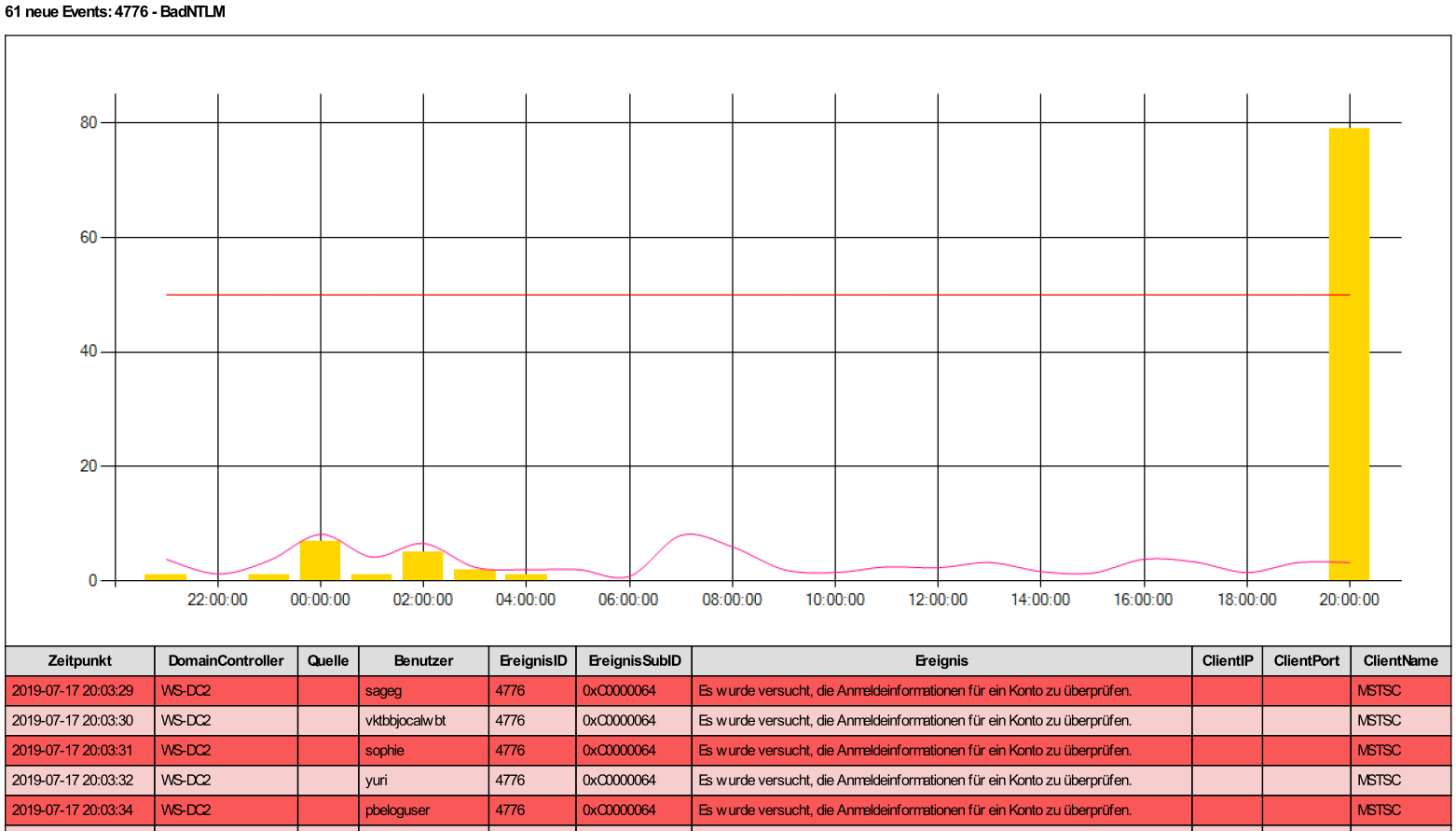
Das Monitoring kann die Angriffsversuche nicht aktiv verhindern – aber der Mailempfänger (also der admin == ich) kann zeitnah reagieren!
Zusammenfassung
Angriffe gehören in unserer vernetzten Welt zum Alltag. Es geht zu bestimmt 99% nicht um euch oder eure Firma. Fast immer sind es automatisierte und gestreute Angriffe. Wählt also aus der breiten Palette von Schutzmaßnahmen großzügig aus. Testet und schult euch und eure Kollegen. Baut euch ein Monitoring auf. Und ganz wichtig: überlegt euch schon heute eine Antwort auf die Frage „Wie reagiere ich richtig?“
Stay tuned!
PS: Den Artikel gibt es hier auch als PDF.
PPS: Das Script „SecEv-Monitor“ hat noch ein paar kleine Kinderkrankheiten. Daher möchte ich es jetzt noch nicht veröffentlichen. Ich nehme aber gerne Voranmeldungen entgegen. 🙂