
Inhaltsverzeichnis
Einleitung
Für meine SIEM-VM brauche ich viel Speicherplatz, damit ich die Daten lange aufbewahren kann. Zugleich möchte ich aber schnell auf die Daten zugreifen können. Bis gestern hatte ich 2 drehende HDDs im Software-RAID 1verbaut. Ich hatte viel Platz, aber die Geschwindigkeit erinnerte mich an meinem PC von vor 10 Jahren. Das konnte so nicht bleiben. Eine All-Flash-Variante war mir aber dafür einfach zu teuer, denn mein SIEM ist für meine Organisationsgröße durchaus übertrieben. Und die Option, mein Elastic SIEM um einen zweiten Knoten zu erweitern, der dann die Archivdaten übernimmt und diese beiden VMs dann entsprechend auf NVMe und HDD zu verteilen, ist eben auch ein hoher Aufwand.
Da kam mir die Idee, Software Defined Storage (SDS) vom Windows Server zu verwenden. Das hatte ich damals mit meinen Windows Server 2012R2 Hyper-V’s schon einmal gemacht. In diesem Beitrag möchte ich zeigen, wie und ob das funktioniert.
Hintergrundinformation
Mit Software Defined Storage versucht Microsoft – wahrscheinlich für seine eigenen Rechenzentren – Geld zu sparen, indem es professionelle Speicherlösungen ohne teure Hard- und Software von Drittanbietern ermöglicht. In meinem Fall nutze ich Speicherpools mit Speicherebenen. Dabei werden mehrere Datenträger unterschiedlicher Medientypen zu einem gemeinsamen Datenträger zusammengefasst. Die komplette Ansteuerung der Hardware übernimmt das Windows Betriebssystem. Es erkennt auf einer Block-Ebene, welche Daten häufiger gelesen werden. Diese werden dann auf den Flash-Speichern platziert. „Kalte“ Datenblöcke landen automatisch auf den langsameren, drehenden Festplatten. Neue Dateien werden auf zuerst den schnellen Flash-Speichern geschrieben. Diese arbeiten dann wie ein SchreibCache. Zusätzlich lässt sich das Ganze mit Redundanzleveln (Mirror oder Parity, vergleichbar mit RAID1 und RAID5) ausstatten. Es werden keine teuren Hardware-RAID-Controller benötigt.
Schematisch schaut mein Aufbau so aus: Ich verwende 2 schnelle NVMe-Speicher mit weniger Platz und 2 große, langsame HDDs. Diese kombiniere ich zu einem virtuellen, gespiegelten Datenträger – entfernt vergleichbar mit einem hybriden RAID10:
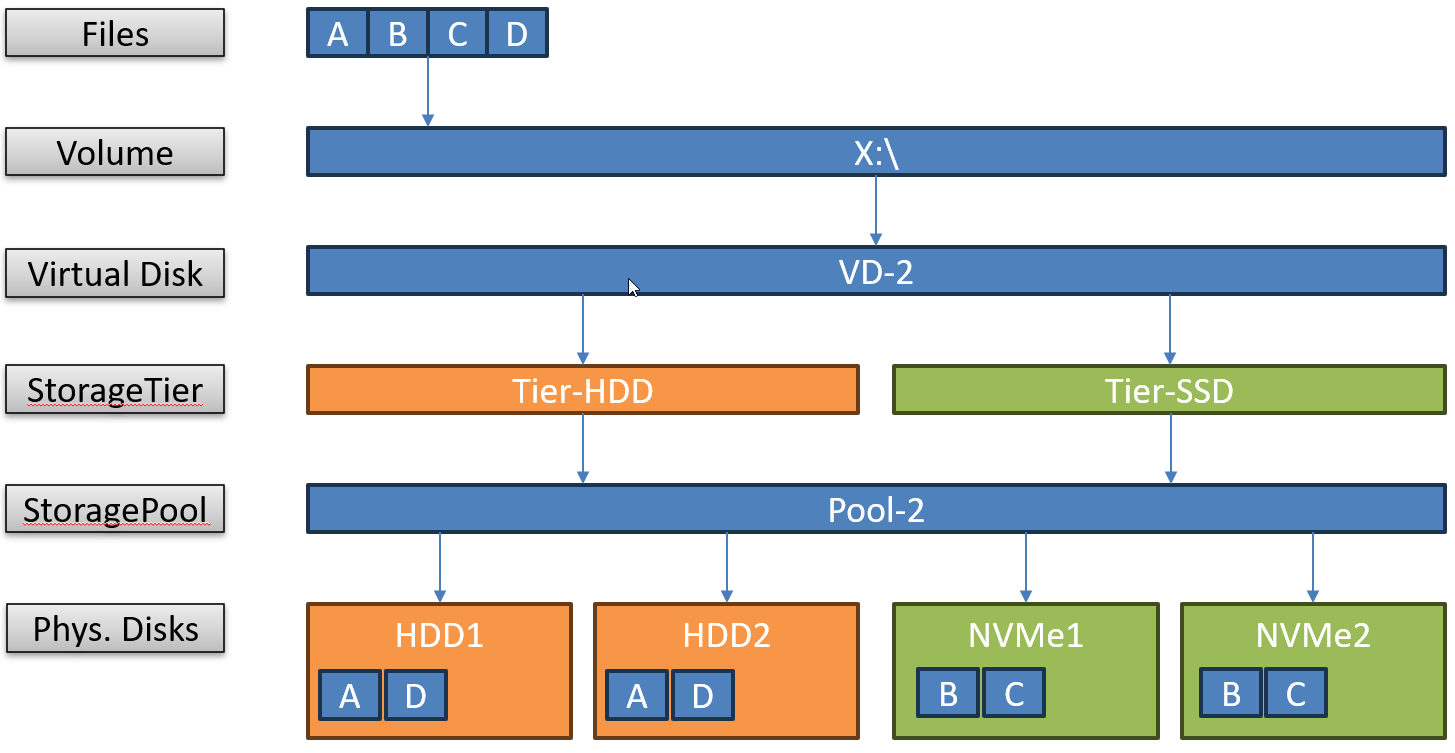
Man kann sehr granular definieren, welche Funktion die unterschiedlichen Medientypen (HDD, SSD, NVMe) erhalten, z.B., ob diese ausschließlich als Cache oder zusätzlich auch als Capacity-Speicher genutzt werden sollen. Im 2. Fall verbleiben „heiße“ Datenblöcke nach Möglichkeit auf den schnellen Speichern, diese altern dann aber entsprechend.
Leistung der einzelnen Komponenten
Ich verbaue 1 Samsung 990 Pro NVMe PCI4 und einen 1 Samsung 980 Pro NVMe PCI4 mit je 1TB und zwei Western Digital Red Plus mit 4TB. Insgesamt kommt da dann ein gespiegelter und getierter Datenträger mit brutto 5TB heraus.
Im ersten Schritt interessiert mich aber, wie die Komponenten einzeln angesprochen reagieren. Dafür habe ich auf den 4 Datenträgern je eine Partition erstellt und dann mit CrystalDiskMark die Performance gemessen. Das sind die Ergebnisse:
Leistung der Samsung 990 Pro 1TB
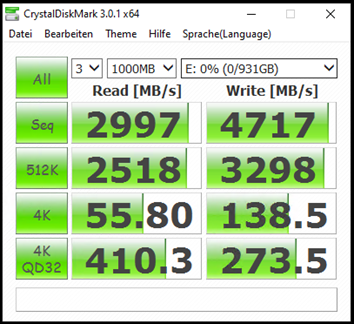
Der Speicherriegel ist in einem PCI4 Adapter verbaut, der mit PCIx4 ans Mainboard angeschlossen ist. Dieser bremst offenbar etwas aus, denn die NVMe ist neu und kann bestimmt mehr leisten. Aber die Werte sind mehr als ausreichend.
Leistung der Samsung 980 Pro 1TB
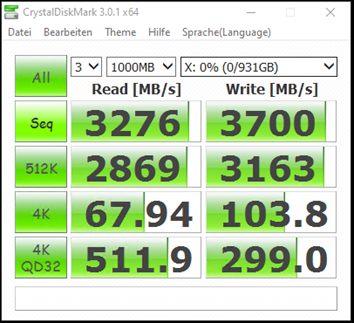
Diese NVMe ist direkt ans Mainboard angeschlossen und wird auch aktiv gekühlt. Auch hier würde mehr gehen. Offenbar bremst meine Hardware etwas aus.
Leistung der ersten WD Red Plus 4TB
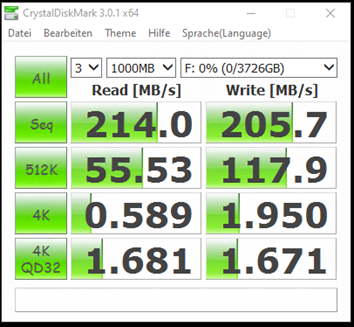
Die Werte sind für eine mit 5.400U drehende Festplatte in Ordnung.
Leistung der zweiten WD Red Plus 4TB
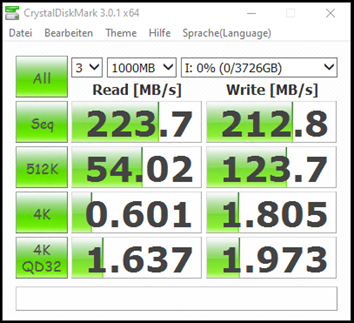
Selbst bei gleicher Hardware gibt es Streuungseffekte bei den Messungen.
Aufbau eines Software Defined Storage
Konfiguration des Speicherpools
Jetzt wird es Zeit für den Software Defined Storage. Im ersten Schritt lösche ich die 4 Testpartitionen, denn die Datenträger müssen komplett leer sein. Die Konfiguration wird im Server Manager vorgenommen. Alternativ kann auch die PowerShell verwendet werden. Im Nafigationseintrag „Datei- und Speicherdienste“ finde ich die Speicherpools. Hier werden die leeren Datenträger im „primordial Pool“ angezeigt. Aus diesen kann ich einen neuen Speicherpool erstellen:
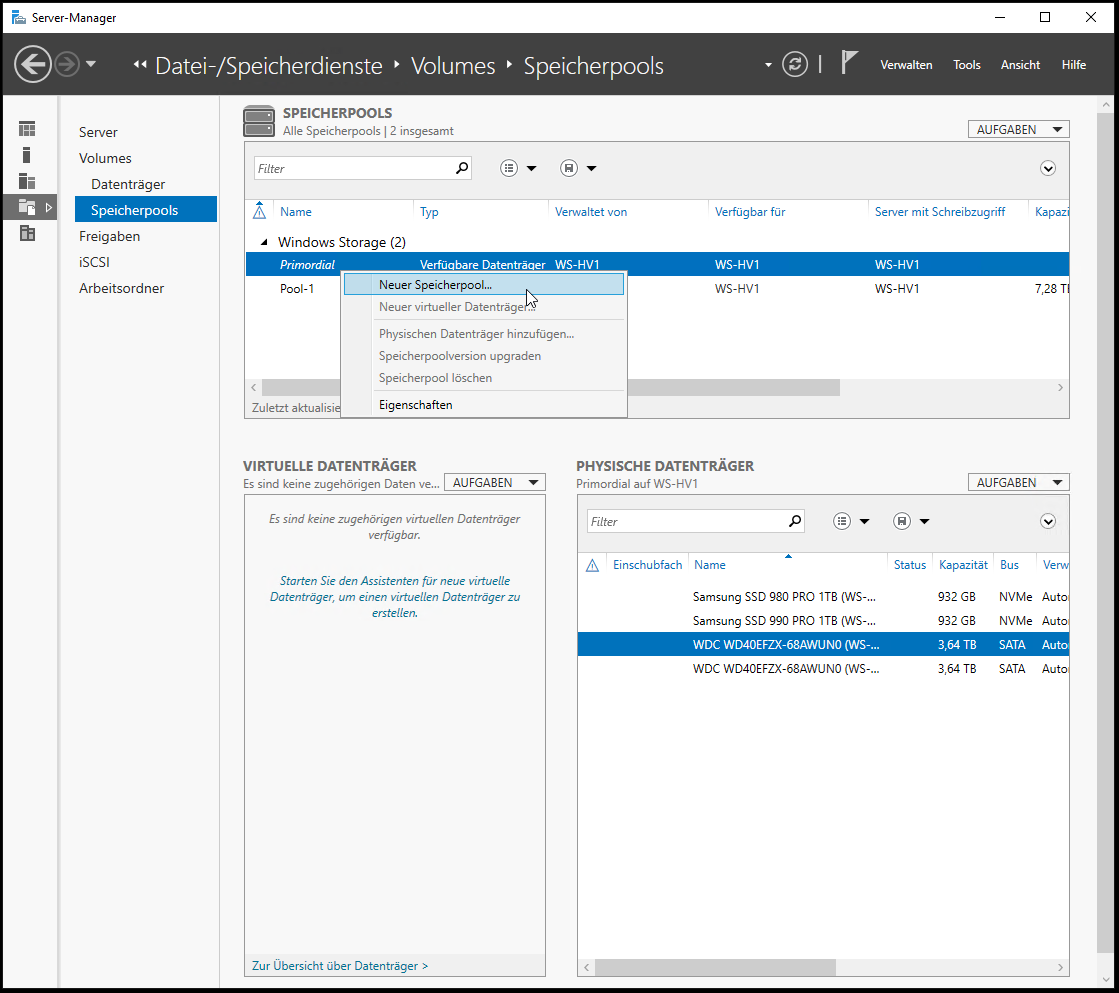
Da ich schon einen Pool-1 habe, erstelle ich nun einen Pool-2:
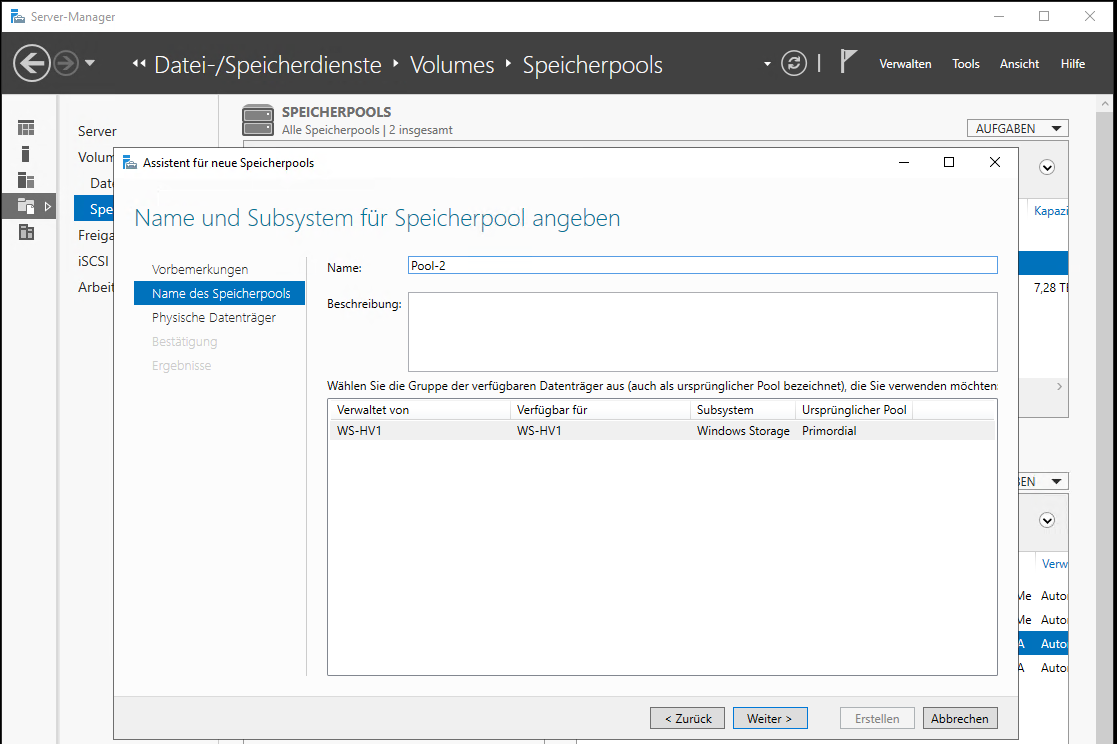
Dann wähle ich die 4 freien Datenträger aus. Der Assistent hat die unterschiedlichen Medientypen bereits erkannt:
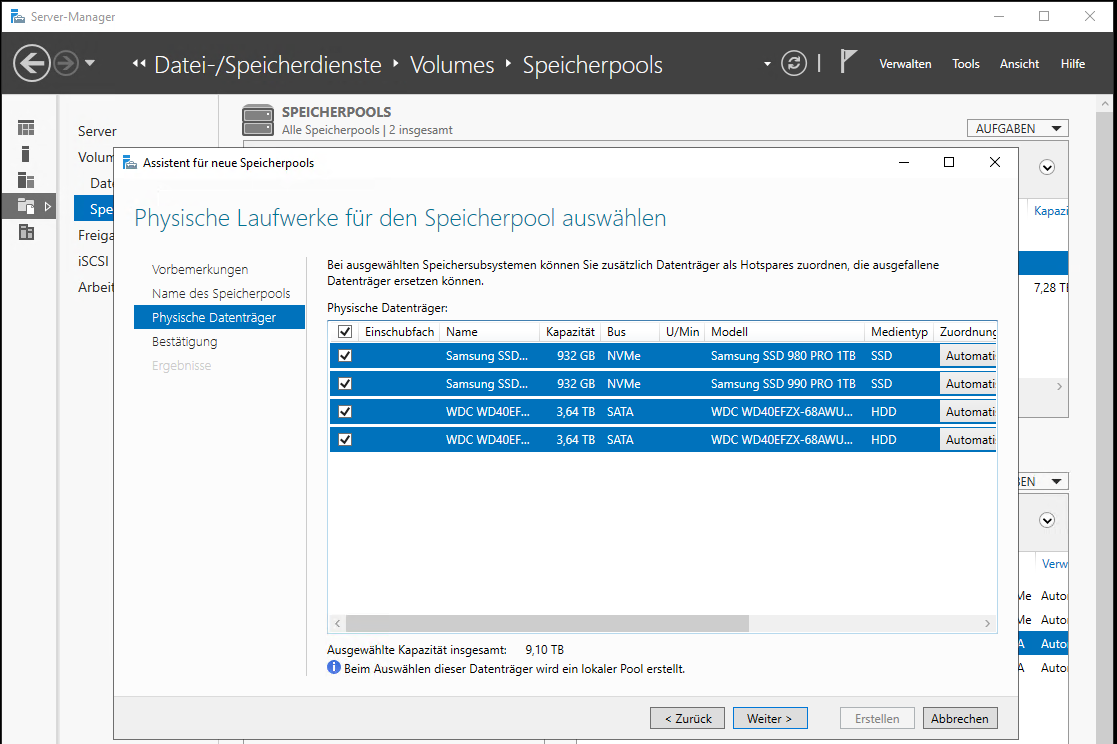
Danach klicke ich auf „erstellen“. Der Pool ist also erst einmal nur eine Definition zusammengehöriger Datenträger. Diese werden nun auch nicht mehr in der klassischen Datenträgerverwaltung angezeigt:
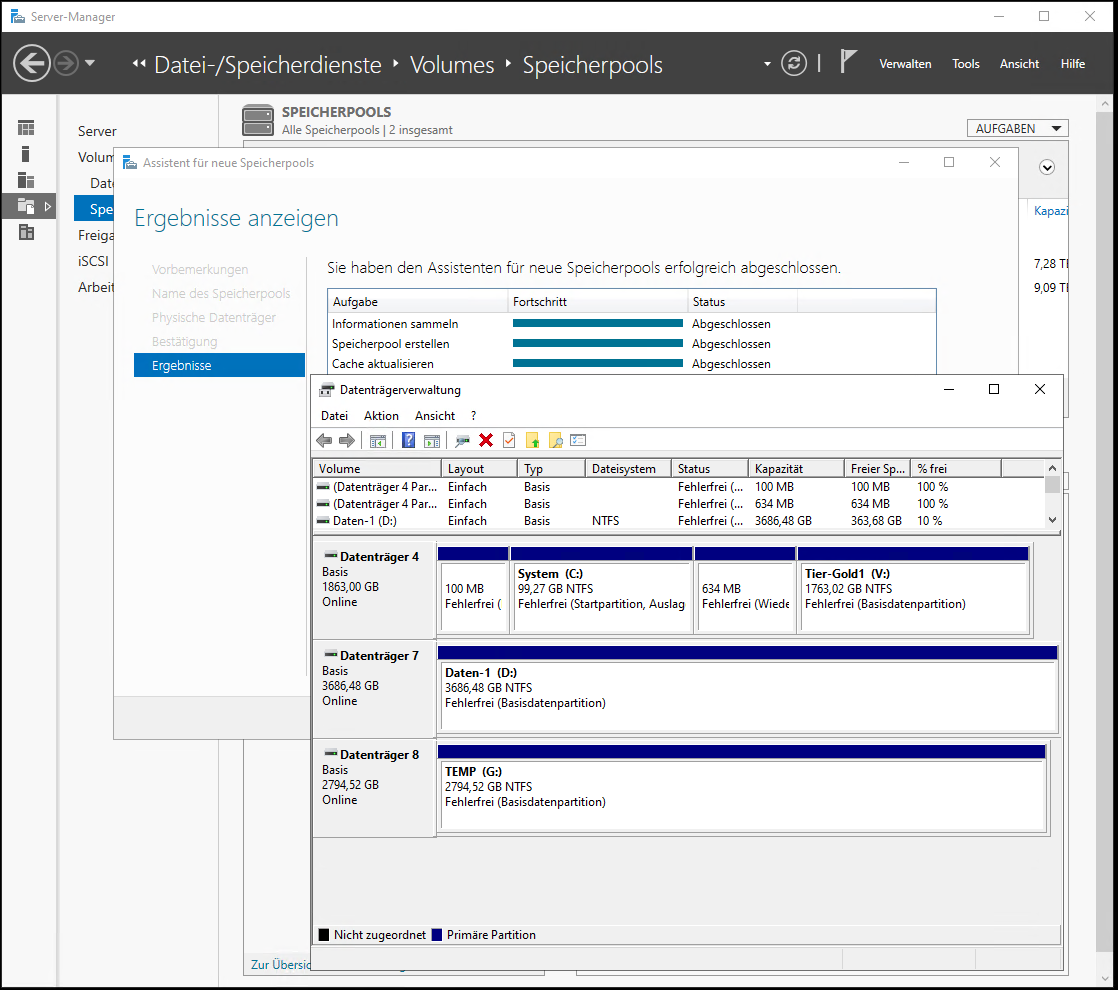
Aufbau des virtuellen Datenträgers
Über das Dropdown-Menü kann ich nun auf diesem neuen Speicherpool einen virtuellen Datenträger anlegen:
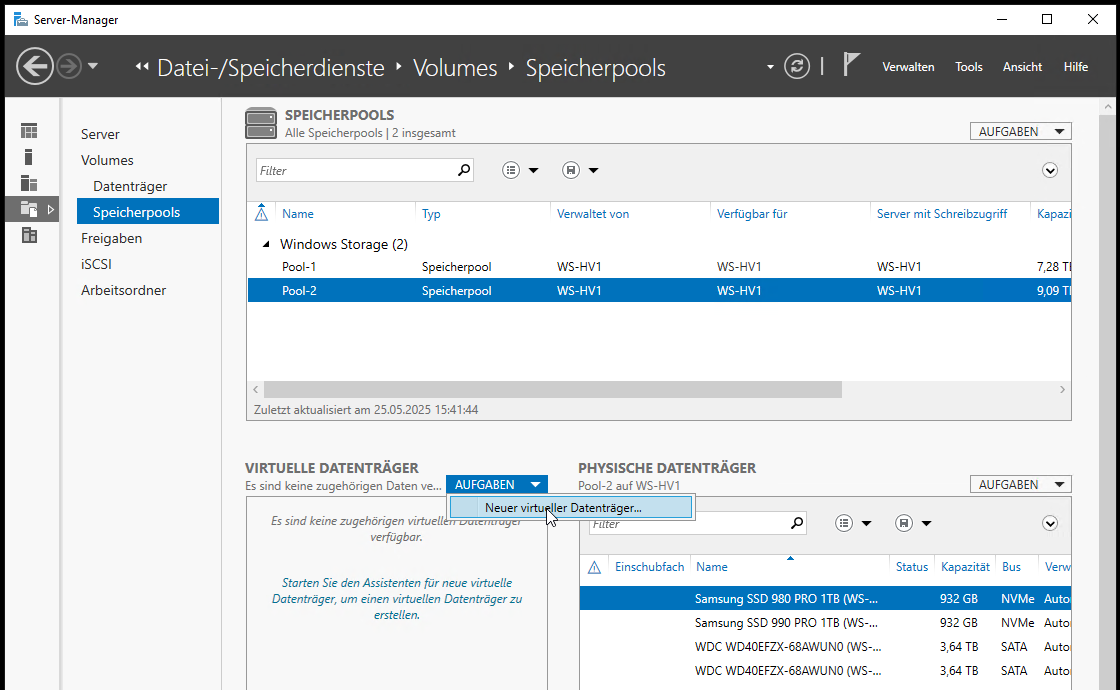
Der virtuelle Datenträger erhält einen Namen und ich aktiviere die Option „Speicherebenen … erstellen“. Das kann nur bei der Anlage vorgenommen werden. Liegen also bereits Daten auf einer VD, dann müssen diese migriert werden, wenn man später Speicherebenen konfigurieren möchte.
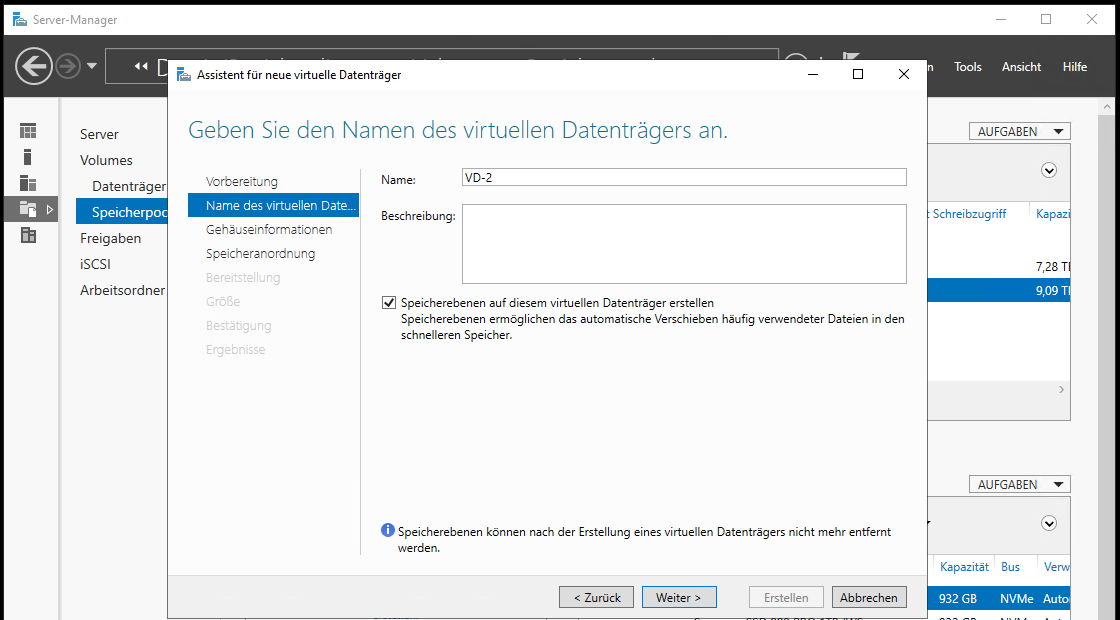
Der Assistent erkennt, dass ich je Medientyp (SSD und HDD) je 2 Datenträger präsentiere. Daher kann ich hier nur zwischen einfacher Datenablage und Mirror auswählen. Mirror entspricht einem RAID1. Das möchte ich gerne für die Ausfallsicherheit verwenden:
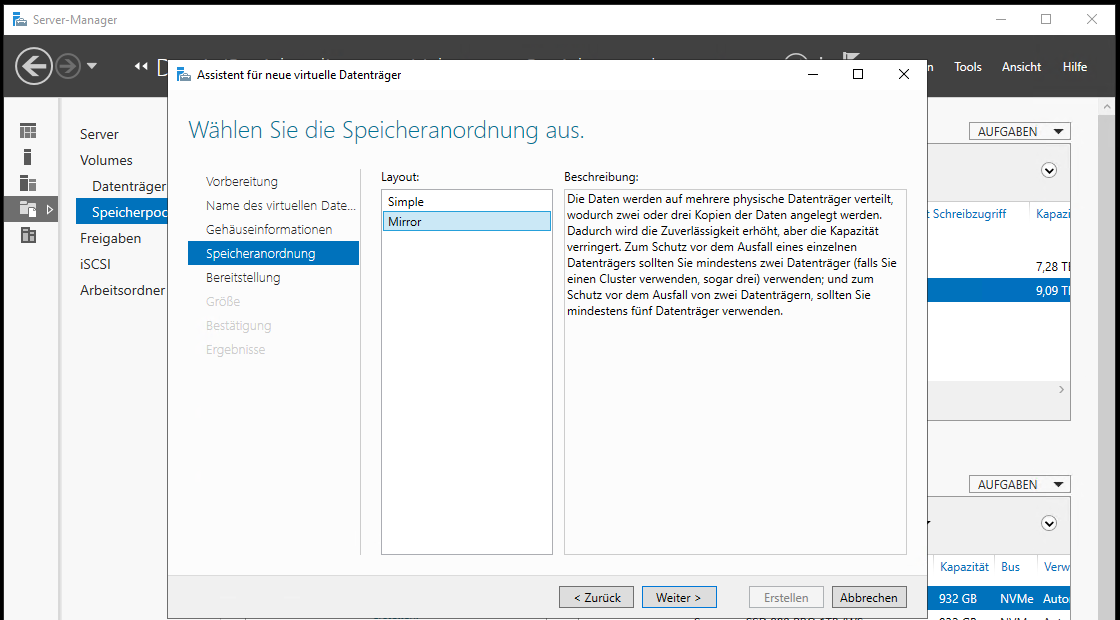
VDs mit Speicherebenen können nicht mit Thin-Provisioning angelegt werden. Ich weise also von Beginn an den kompletten Speicherplatz zu:
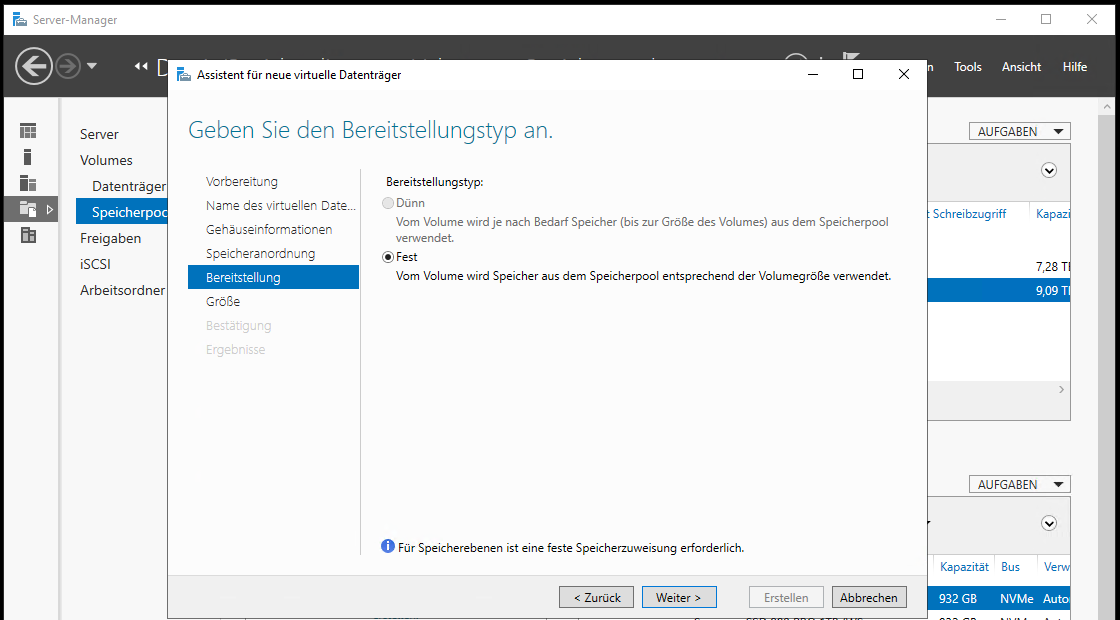
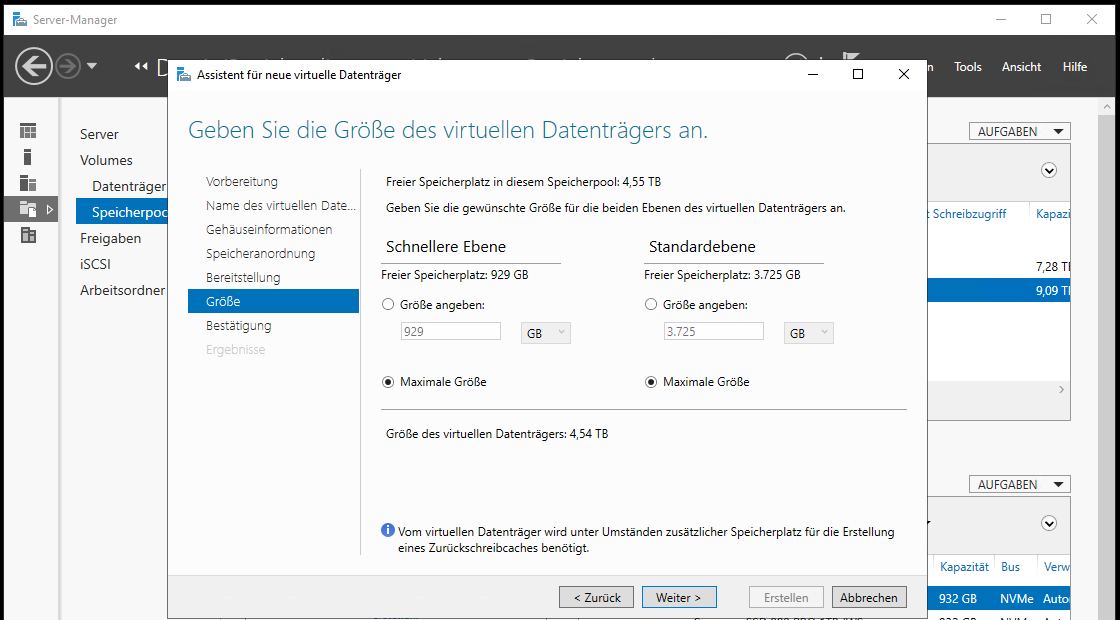
Wobei ich den Speicher auch nur anteilig vergeben könnte, um z.B. einen weitere VD gespiegelt anzulegen, die nur auf NVMe oder nur auf HDD liegt. Ich habe aber noch genug All-Flash für meine anderen VMs, daher vergebe ich alles und erhalte so einen finalen Datenträger mit 4,54TB:
Aber die Erstellung schlägt mit einem Fehler fehl:
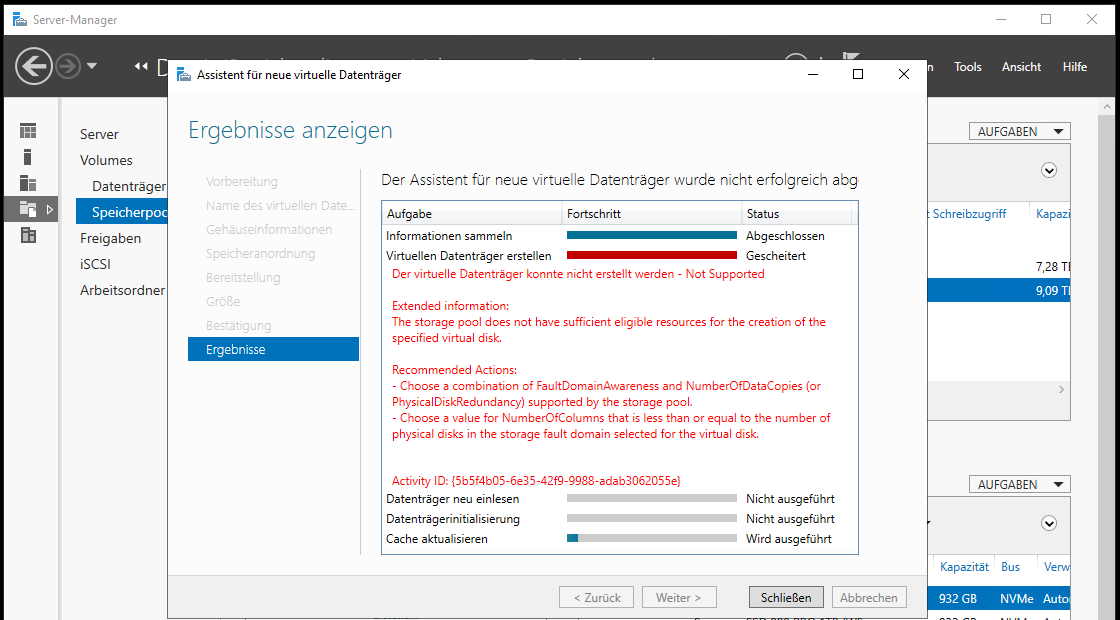
TroubleShooting
Ich versuche es noch einmal, vergebe aber nicht den kompletten Speicher, sondern lasse je Tier ein GB ungenutzt:
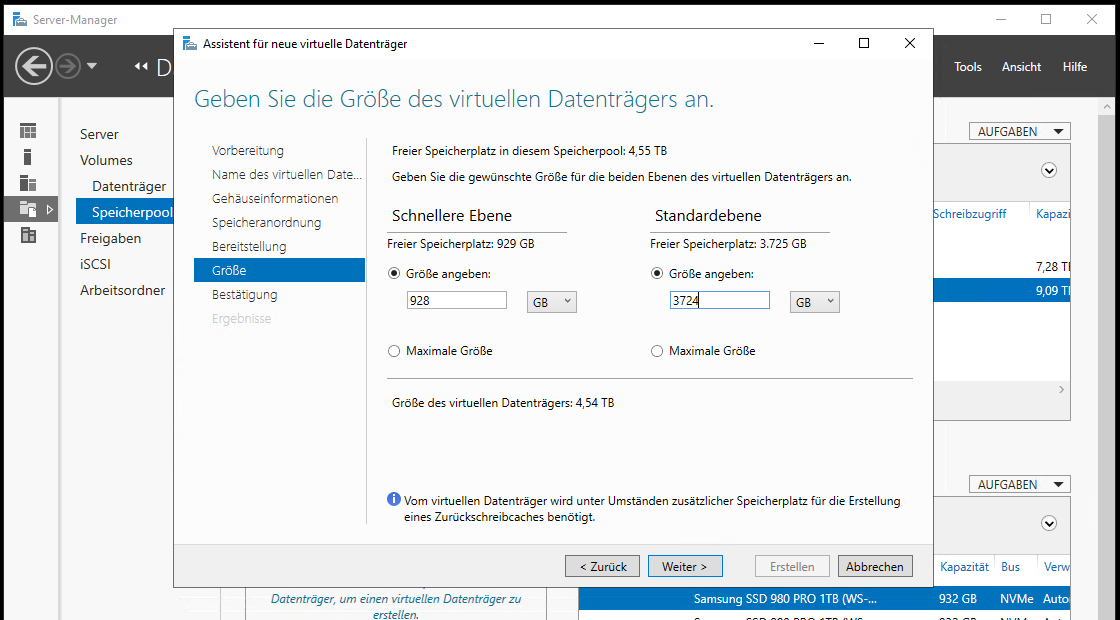
Das war unter Windows Server 2012R2 auch schon so. Manche Dinge ändern sich nie. Der Assistent kann nun die VD anlegen:
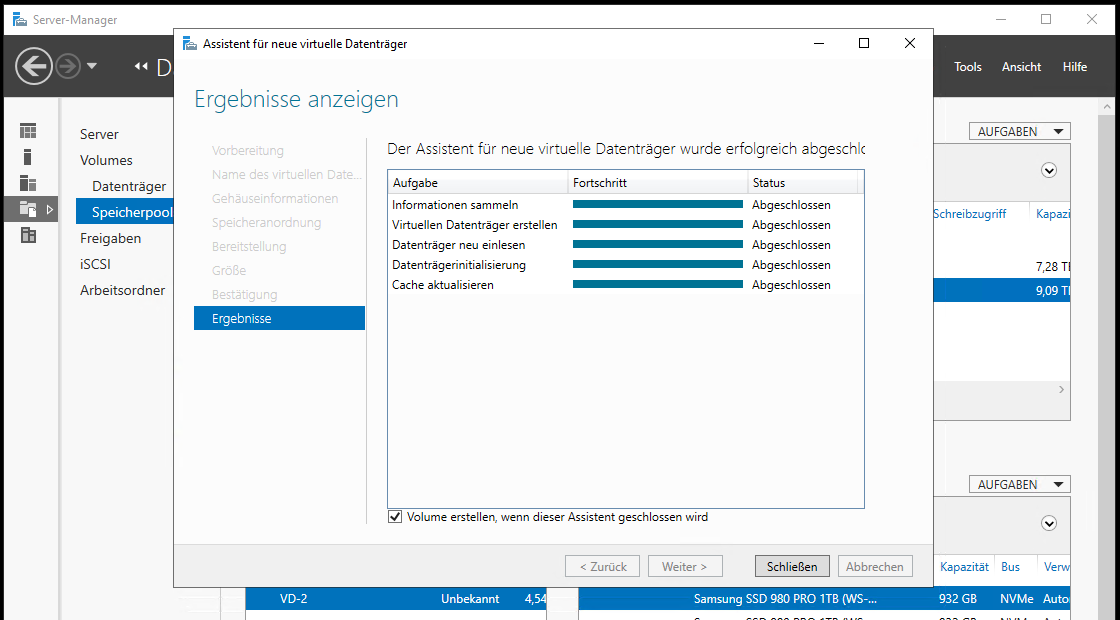
Anlage und Formatierung eines Volumes
Der neu angelegte, virtuelle Datenträger ist nun auch wieder in der klassischen Datenträgerverwaltung sichtbar. Und wie jeder normale Datenträger muss er initialisiert, partitioniert und formatiert werden. Das sollte man besser im Server Manager erledigen, denn dieser kennt eine Einschränkung:
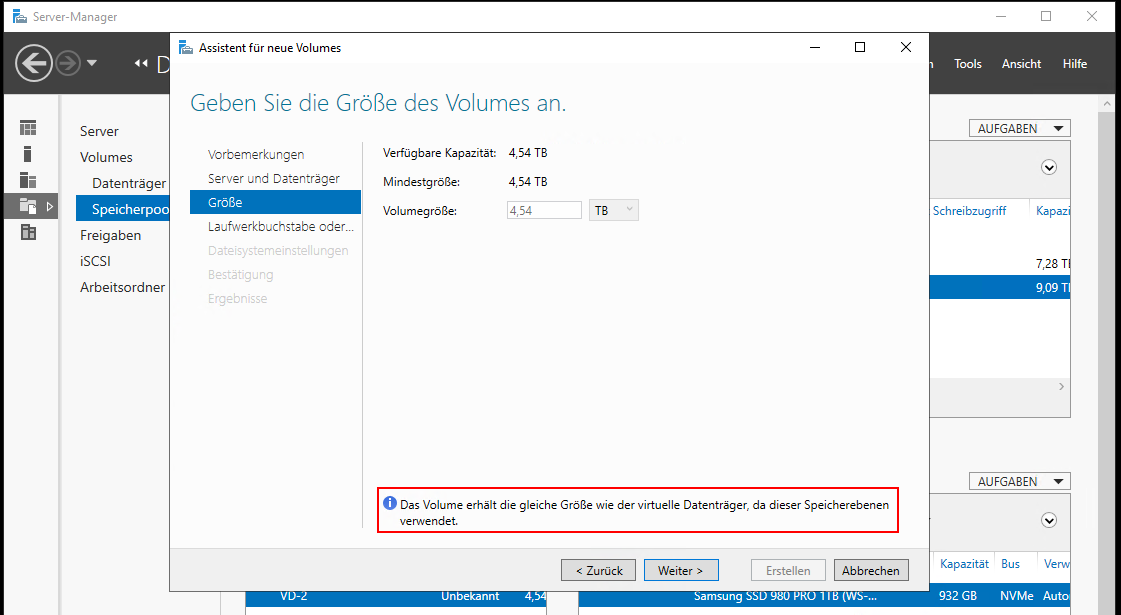
Ich wähle noch einen Laufwerksbuchstaben, NTFS für die Formatierung und eine Laufwerksbezeichnung aus:
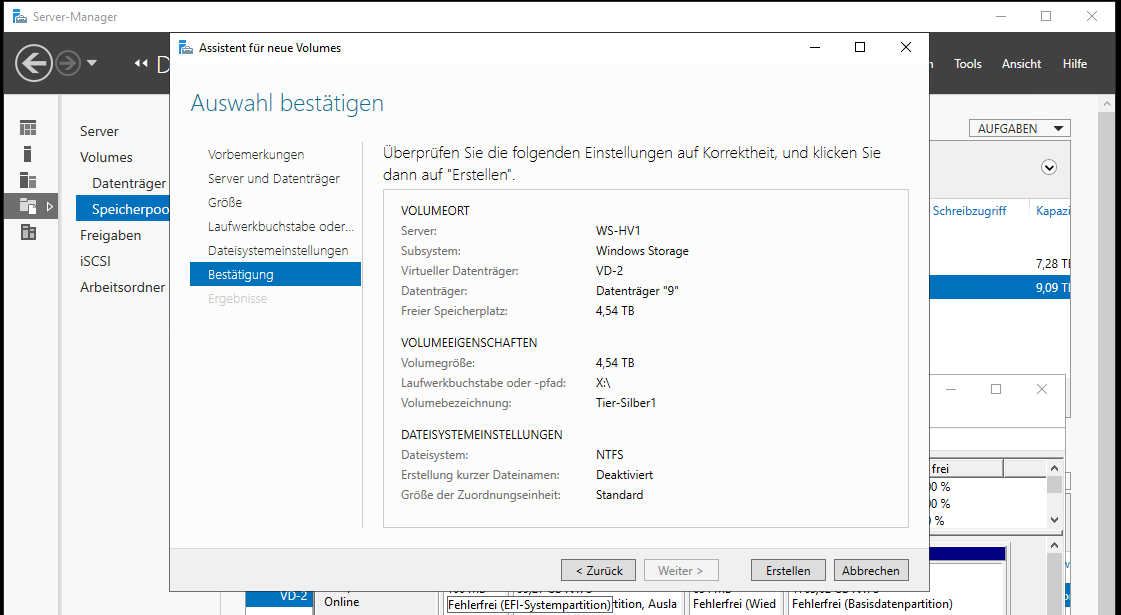
Das wäre auch schon alles gewesen:
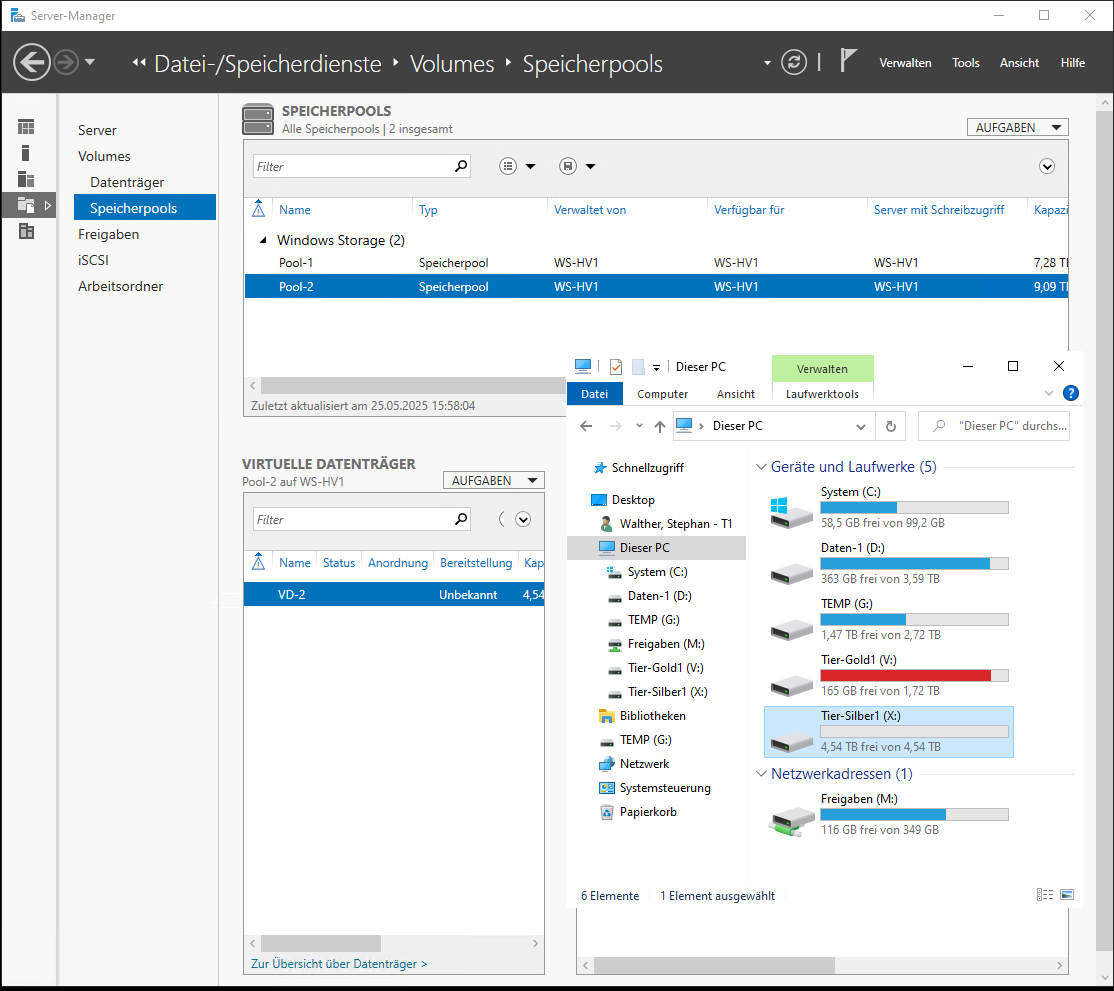
Leistung des Speicherpools – erste Messung
Nun starte ich wieder meinen CrystalDiskMark und werde von dem Ergebnis überrascht, daher habe ich die Messung im ersten Lauf auch abgebrochen:
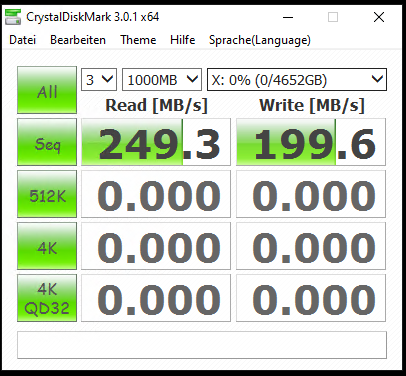
Diese Werte kommen mir bekannt vor. Das ist die Performance der beiden HDDs. Eigentlich sollte aber zuerst der NVMe-Mirror gefüllt werden. Eine kurze Recherche zeigt, dass Microsoft etwas im Windows Server 2022 beim SDS verändert hat und die NVMe anders genutzt werden. Das will ich aber nicht.
Neuerstellung des Speicherpools
Ich entferne das Volume, den virtuellen Datenträger und den Speicherpool und erstelle ihn neu. Dieses Mal verwende ich die PowerShell:
# Variablen
$PoolName = "Pool-2"
$VirtualDiskName = "VD-2"
$DriveLetter = "X"
$DriveLabel = "Tier-Silber1"
$TierSizeSSD = 928GB
$TierSizeHDD = 3724GB
# erstelle Speicherpool aus allen verfügbaren Disks
New-StoragePool `
-FriendlyName $PoolName `
-PhysicalDisks (Get-PhysicalDisk -CanPool $true) `
-StorageSubSystemFriendlyName "Windows*"
# erstelle die Speicherebenen (Tiers)
Get-StoragePool -FriendlyName $PoolName | New-StorageTier -FriendlyName "SSD-Tier" -MediaType "SSD"
Get-StoragePool -FriendlyName $PoolName | New-StorageTier -FriendlyName "HDD-Tier" -MediaType "HDD"
$StorageTiers = @()
$StorageTiers += Get-StorageTier -FriendlyName "SSD-Tier"
$StorageTiers += Get-StorageTier -FriendlyName "HDD-Tier"
# erstelle den virtuellen Datenträger bis zum Volume in einem Arbeitsschritt:
Get-StoragePool -FriendlyName $PoolName |
New-VirtualDisk `
-FriendlyName $VirtualDiskName `
-ResiliencySettingName 'Mirror' `
-StorageTiers $StorageTiers `
-NumberOfColumns 1 `
-StorageTierSizes @($TierSizeSSD;$TierSizeHDD) `
-ProvisioningType "Fixed" |
Initialize-Disk -PassThru |
New-Partition -DriveLetter $DriveLetter -UseMaximumSize |
Format-Volume -FileSystem "ReFS" -NewFileSystemLabel $DriveLabel
# optional: Entfernen des Pools
break
Get-Partition -DriveLetter $DriveLetter | Remove-Partition -Confirm:$false
Get-StoragePool -FriendlyName $PoolName | Get-VirtualDisk | Remove-VirtualDisk -Confirm:$false
Get-StoragePool -FriendlyName $PoolName | Remove-StoragePool -Confirm:$falseHier ist nur ein kleiner Unterschied drin: Das Dateisystem ist nicht mehr NTFS, sondern ReFS. Das wird wohl benötigt, um die NVMe’s als Capacity-Datenträger anzusprechen! (Quelle: cache – Windows storage spaces tiered storage not using nvme drive? – Server Fault, von Microsoft habe ich dazu nichts gefunden!)
zweite Messung
Mit dieser Anpassung ergeben sich folgende Werte:
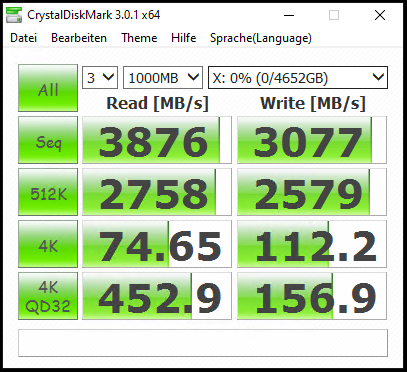
Damit bin ich nun sehr zufrieden. Natürlich wird dieser virtuelle Datenträger diese Performance nur halten, wenn die Daten auch auf den NVMe’s landen. Aber dazu führe ich später eine 3. Messung durch.
Um die Performance und das Verhalten zu messen, habe ich mir ein PowerShell-Script erstellt, dass die Leistungsindikatoren der physikalischen Datenträger in einer Schleife ausliest und deren Ergebnisse in einer csv-Datei speichert. Hier sieht man, wie eine vhdx-Datei von meiner anderen NVMe auf das neue Konstrukt kopiert wird. Die Performance wird durch die ausgelastete Quell-NVMe beeinflusst. Die Daten landen aber auf den beiden NVMe’s:
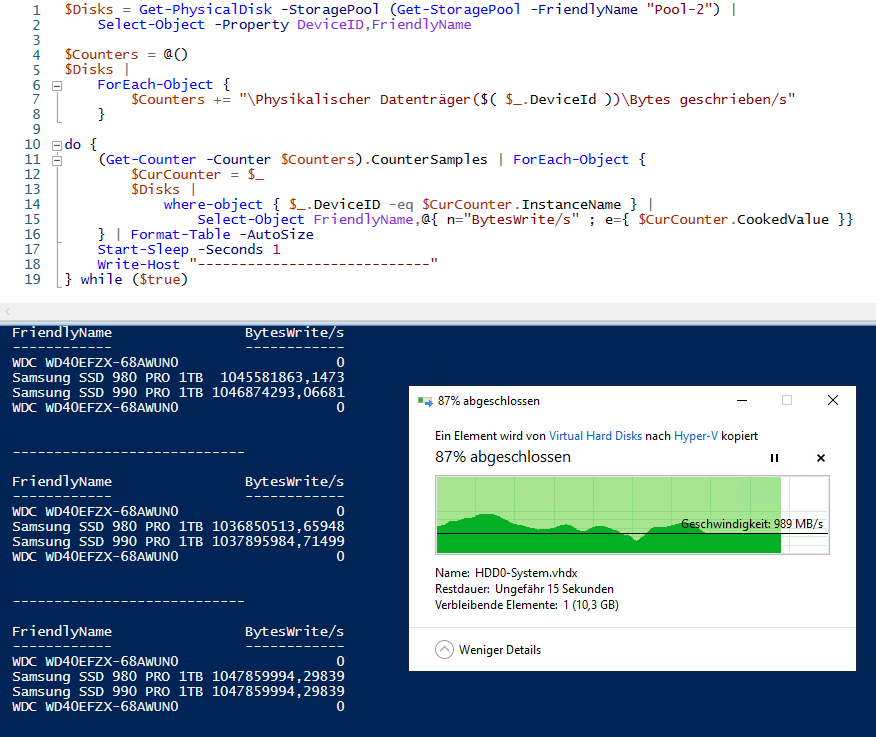
Das sieht soweit gut aus. Jetzt verschiebe ich erst einmal meine SIEM-VM auf diese Konstruktion.
dritte Messung
Während der Verschiebung meiner SIEM-VM habe ich mein Script mitlaufen lassen. Das Ergebnis habe ich dann im Excel weiterverarbeitet. So kann ich nun gut darstellen, die die 4 Datenträger die Datenmenge aufgenommen haben. Im oberen Diagramm seht ihr die Lese- und Schreibzugriffe in MB/s auf die langsamen HDD’s. Im mittleren Diagramm sieht man die Lesezugriffe der schnellen NVMe’s und darunter die Schreibzugriffe auf die NVMe’s:
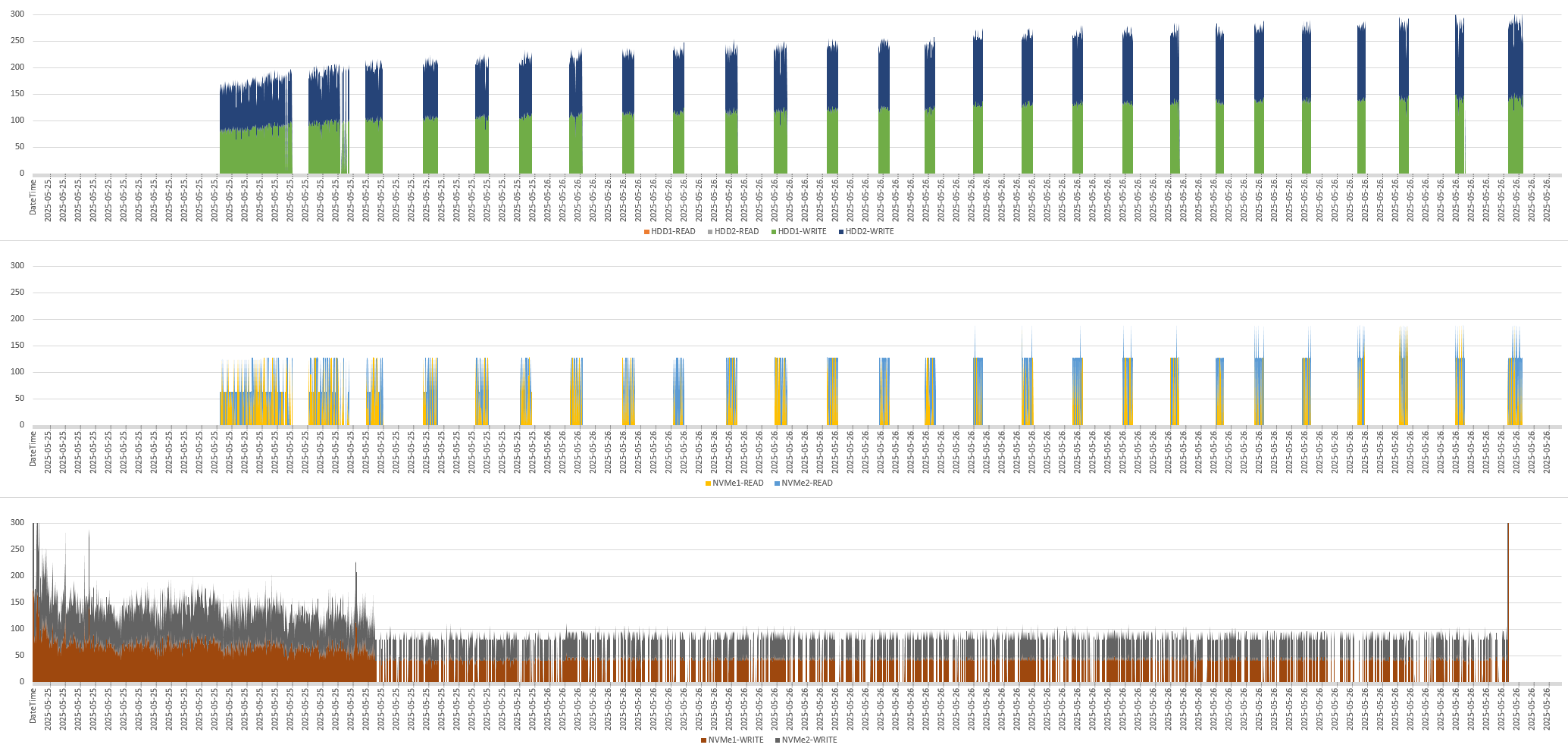
Und das ist über die Zeit passiert:
- Zu Beginn wurden Daten komplett auf die beiden NVMe’s geschrieben. Dabei wurde beide mit den gleichen Daten beschrieben, um die Anforderung „Mirror“ zu erfüllen. Das erkennt man an der brauen und der grauen Fläche im unteren Diagramm (Die Diagramme sind gestapelt). Während dieser Zeit waren die HDD’s lastfrei.
- Dann wurde zusätzlich von den NVMe’s auch gelesen und Windows begann, Daten auf die HDD’s zu schreiben. Da hat Windows gemerkt, dass die NVMe’s langsam voll laufen. Im Hintergrund hat es also erste Daten auf die langsameren HDD’s ausgelagert, ohne die Verschiebeaktion zu verlangsamen.
- Und das Auslagern wurde dann intervall-artig wiederholt, weil immer neue Daten dazukamen. Ab dem 2. Viertel kamen die Daten von einer temporären Auslagerungs-Disk, die ich über langsames USB am Server angeschlossen habe. Das erklärt dann die unterbrochenen Schreibzugriffe im unteren Diagramm.
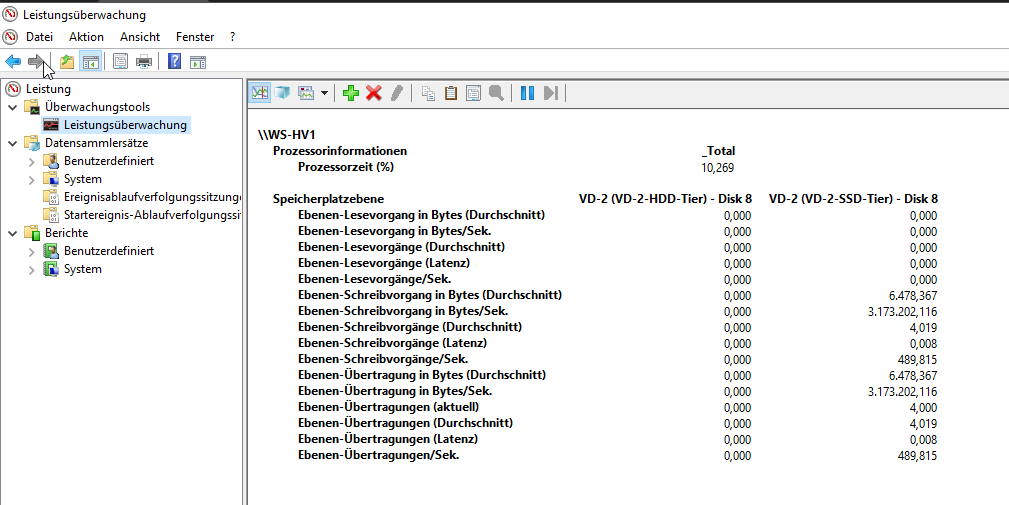
Auch in der Leistungsanzeige (perfmon) kann man das gut auslesen. Hier habe ich mal die Indikatoren für die Speicherebenen ausgelesen. Man erkennt, dass nur das SSD-Tier mit den schnellen NVMe’s genutzt wird. Und das ist fast dauerhaft so:
Fazit
Die Verschiebeaktion meiner SIEM-VM ist schon mehrere Tage abgeschlossen. Insgesamt fühlt sich deren Web-UI wieder sehr flüssig an und auch die Suchen von aktuellen Daten ist sehr schnell. Die HDDs sind meist lastfrei, was sich am Stromverbrauch und dem Betriebsgeräusch bemerkbar macht. Der Umbau hat also funktioniert und erfreue mich an der gewonnenen Performance. 🙂
Stay tuned